


Winter Heating: unexpected economic resilience in the US and Europe; large language model battles heat up
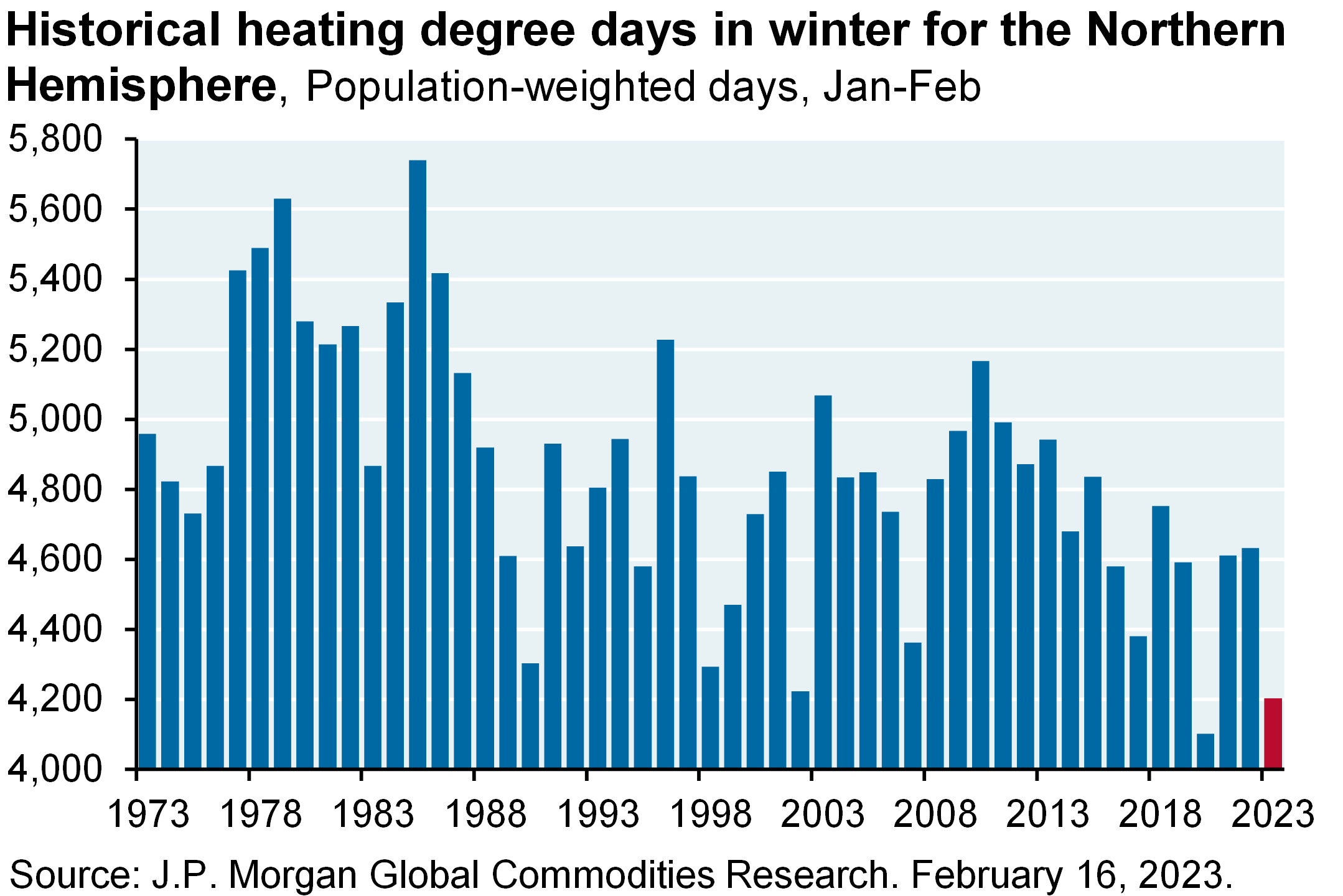
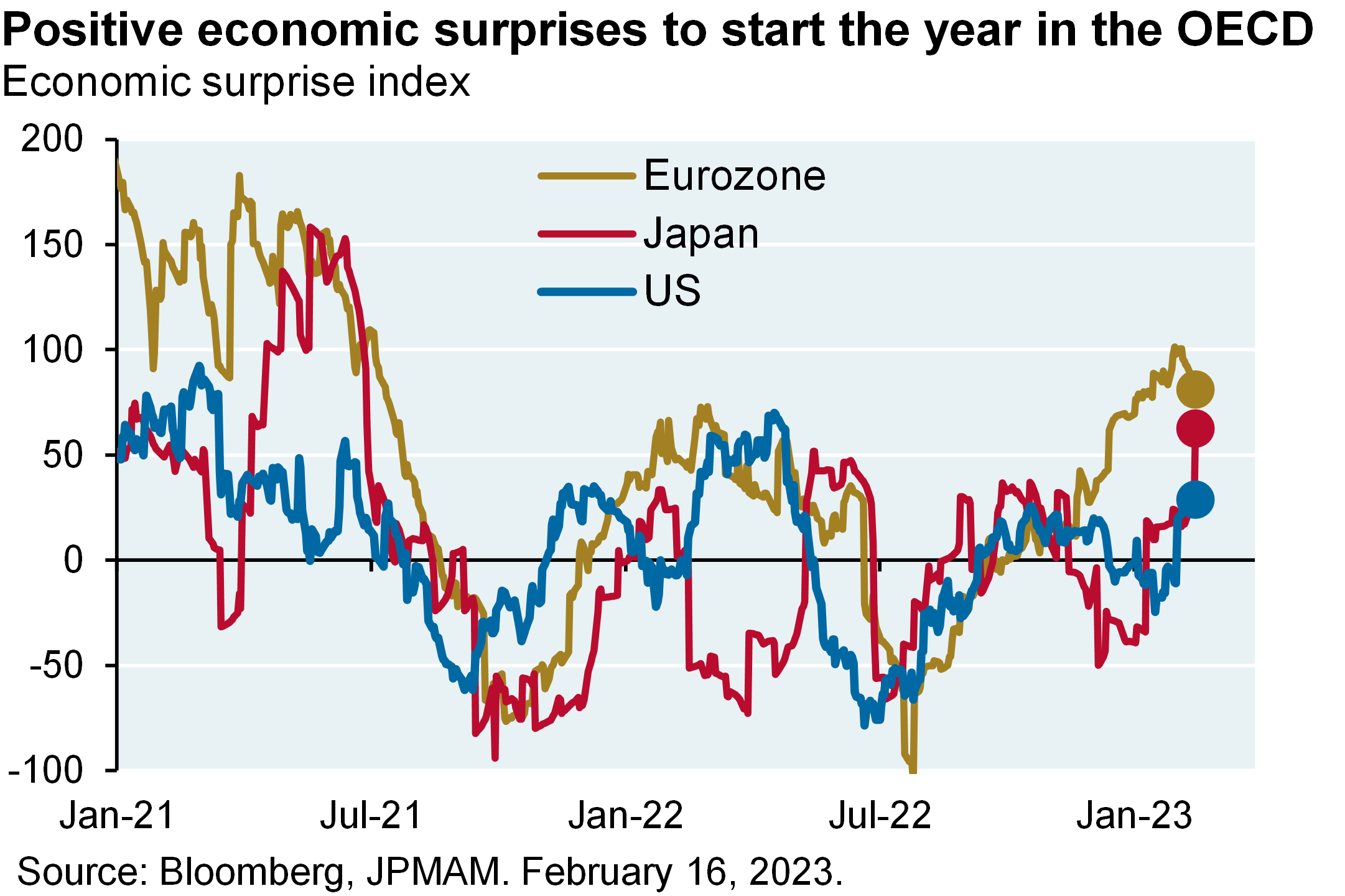
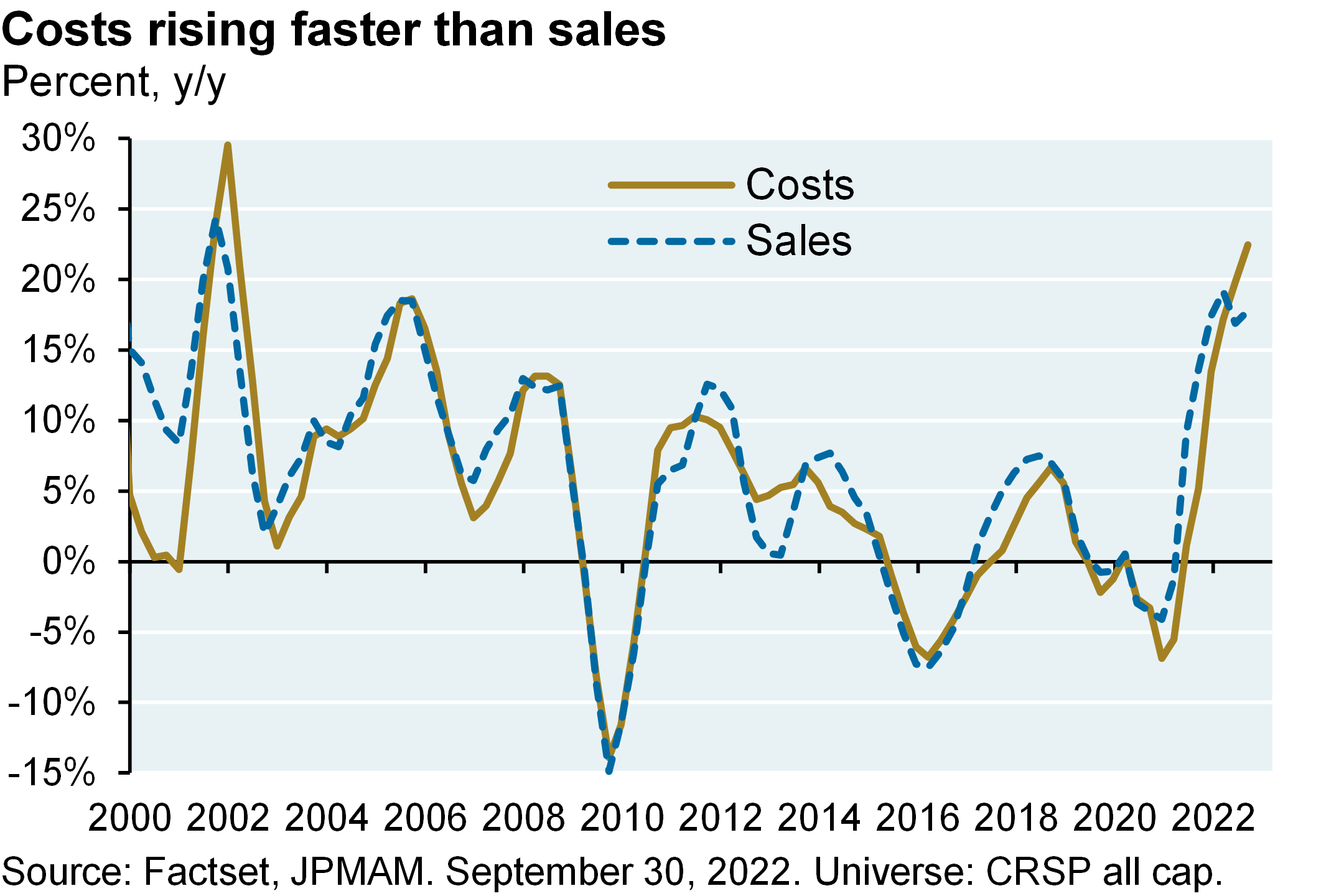
A warm Northern Hemisphere winter has coincided with a flurry of positive economic surprises in the US, Europe and Japan. The US list of positives includes retail sales, manufacturing output, the highest NAHB housing market index in 5 months, resilient residential construction employment, a rebound in the PMI services index, jobless claims back at low levels, a surge in the household survey of employment growth, a miniscule high yield default rate, stable capital spending projections and a 70% decline in the number of companies citing labor shortages. Also: GDP tracking models are back in positive territory everywhere in the developed world except the UK. Combine this with Europe surviving the winter with a high level of gas inventories and China’s re-opening, and the world growth outlook appears less troubling than it did last fall.
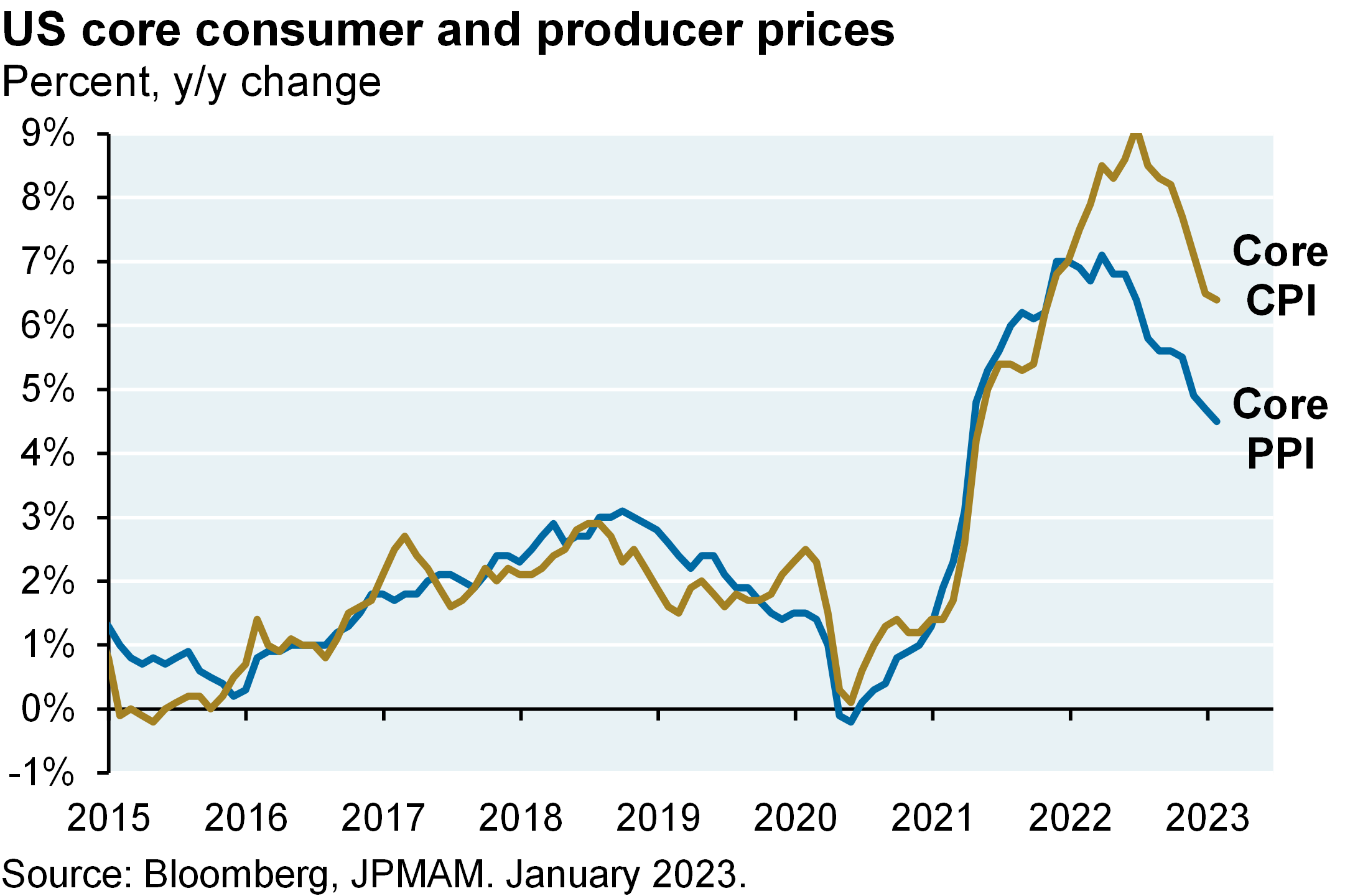
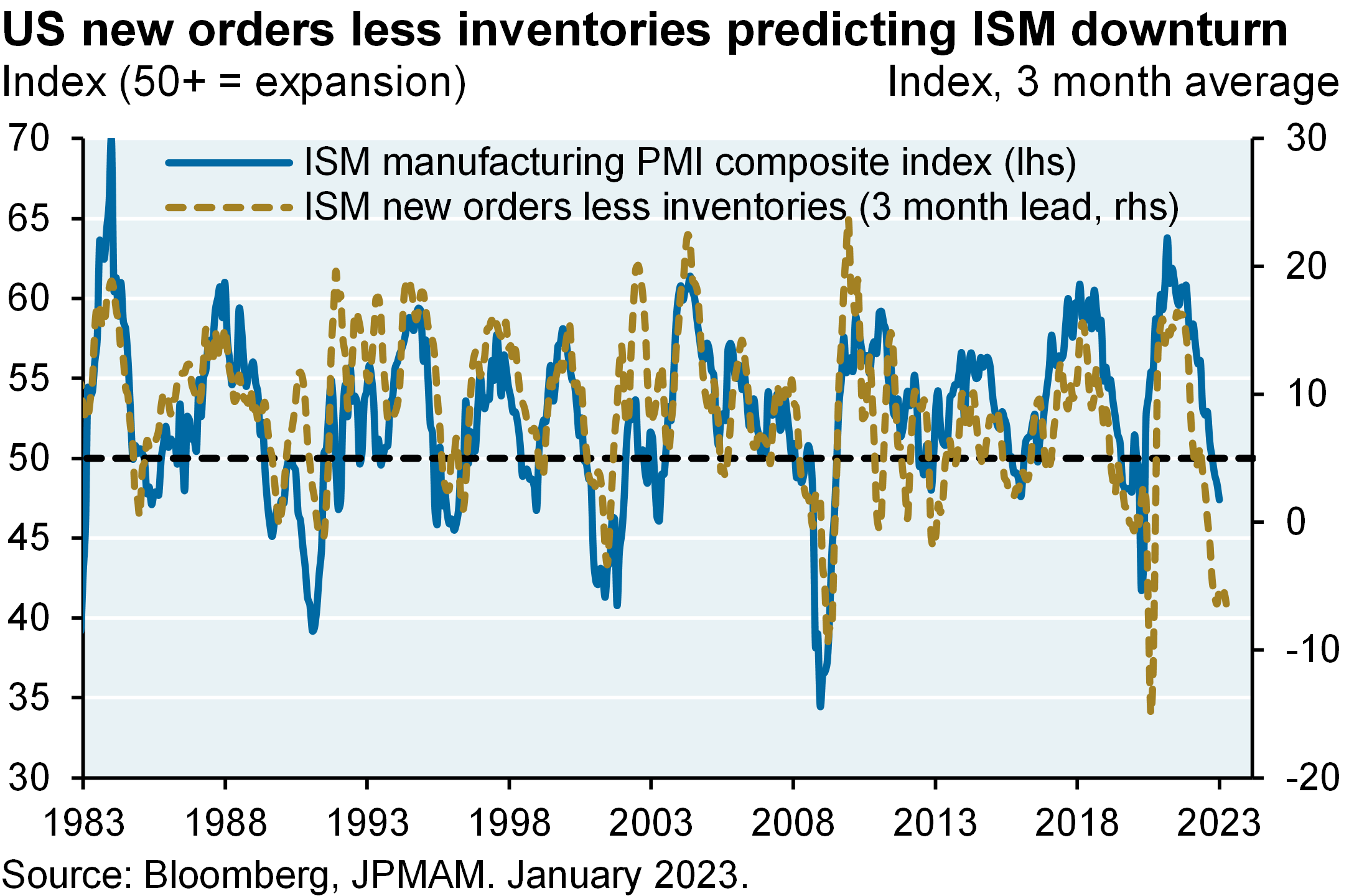
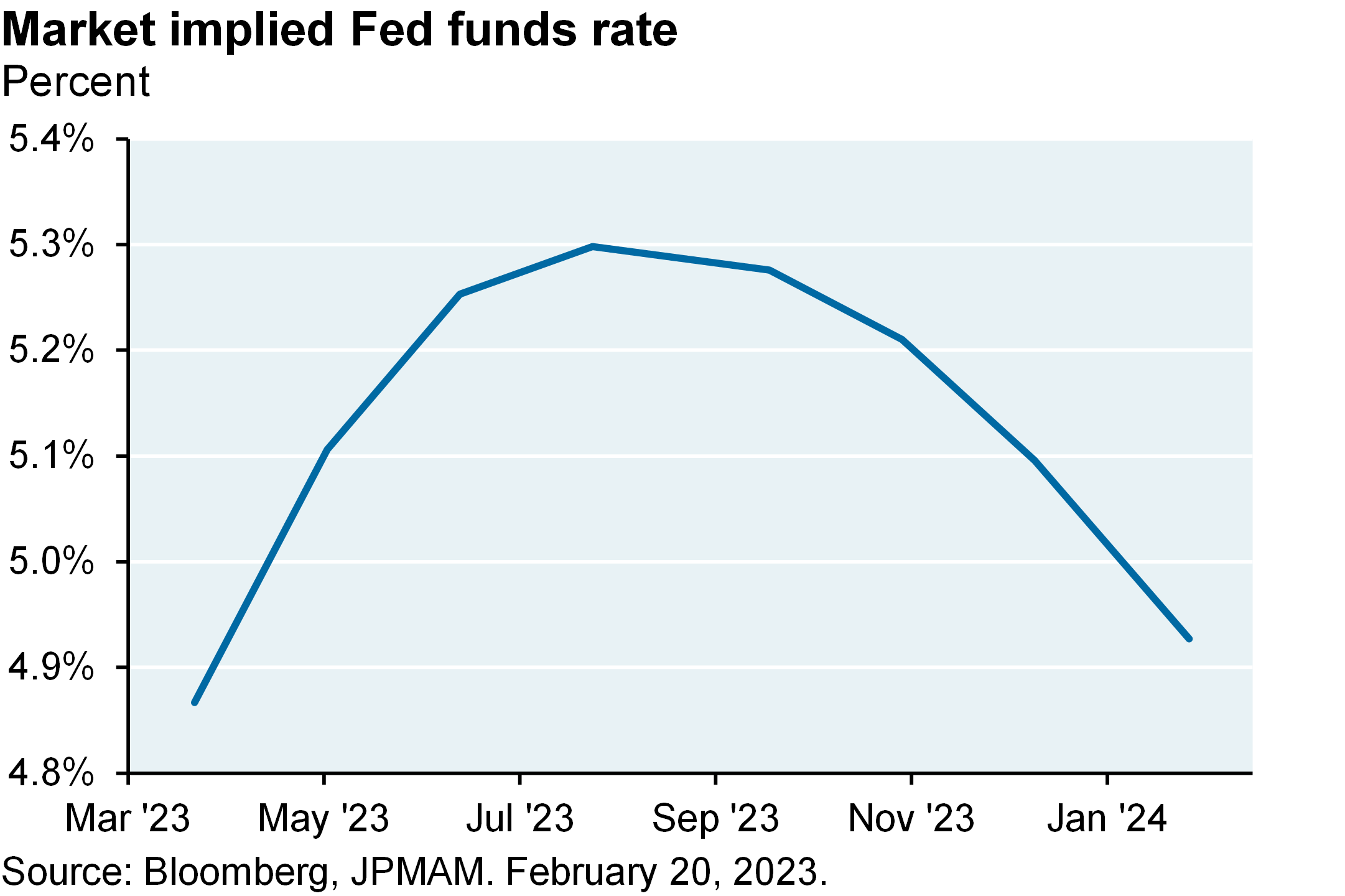
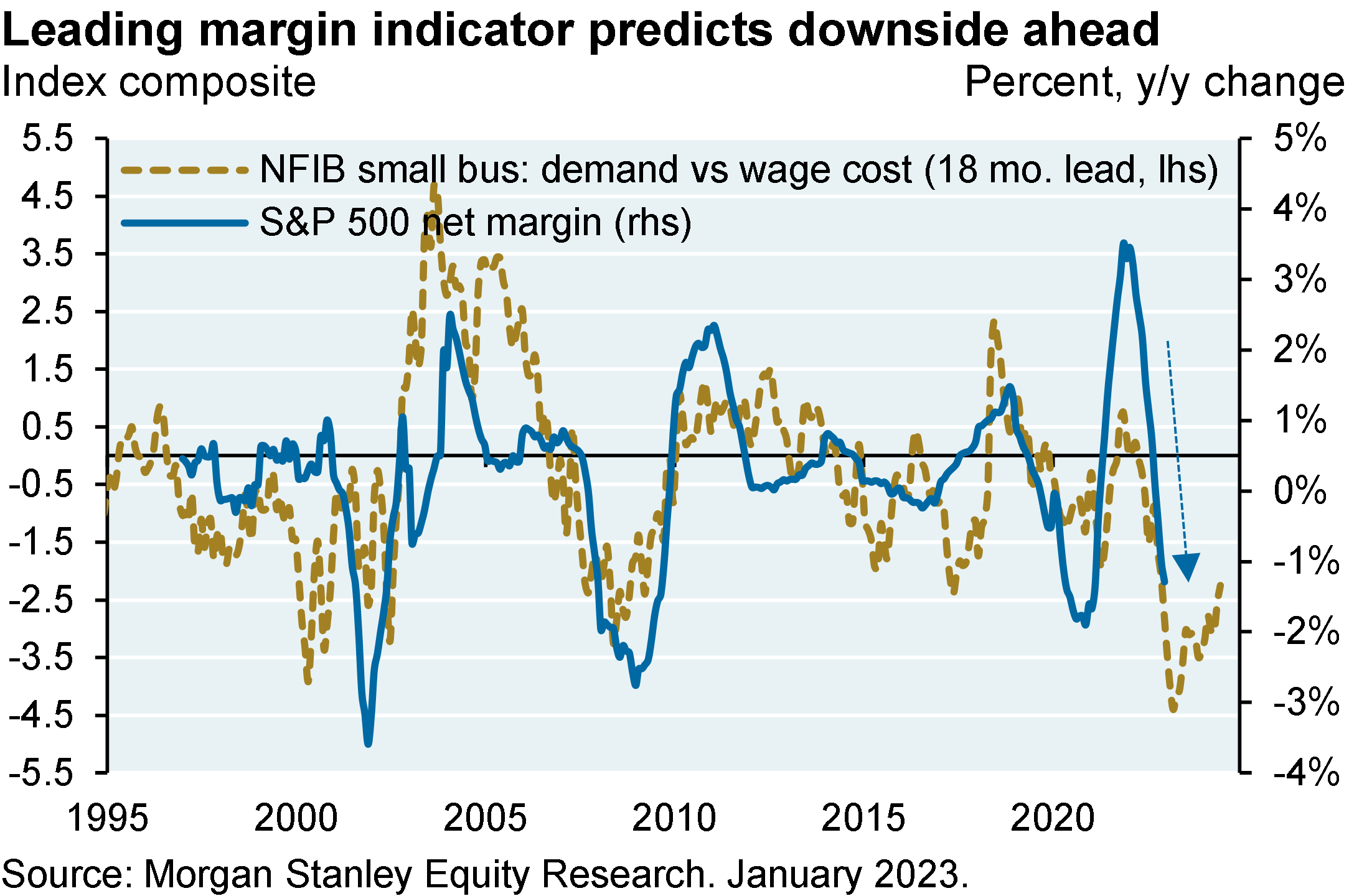
The problem: policy rates are not normalized yet. Despite the fastest Fed tightening cycle on record, real US 3-month and 10-year yields are still negative when based on trailing inflation measures. Consumer and producer price increases are falling as we expected they would but it’s too soon for the Fed to pause here. It also seems unlikely that the Fed or ECB will be able to cut rates later this year, unless they overshoot first. Will economic resilience prompt the Fed to tighten even more than markets expect? I think it would take more than a couple of months of positive surprises for the Fed to hike by 50 bps. We still see weakness ahead in our preferred leading indicator (new orders vs inventories) and deflation in the housing pipeline. Bottom line: 2-3 more Fed hikes ahead, and a mild US recession whose likelihood and possible severity may be shrinking.
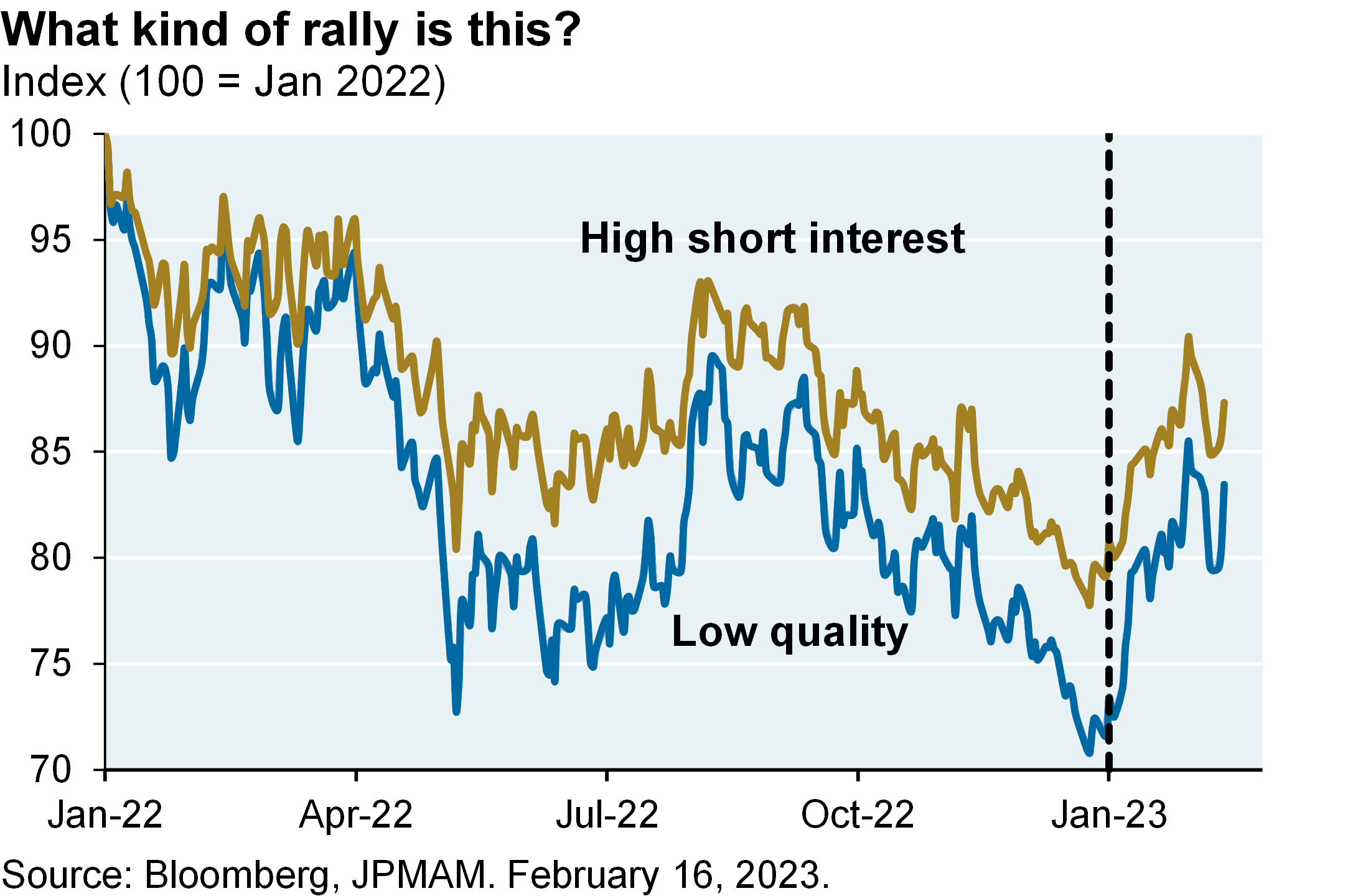
The US equity market rally this year is partially built on appreciation of low-quality and high short-interest stocks, a $6 trillion rebound in the global money supply, and the view that Fed hikes will not do much damage to the economy or earnings. With this backdrop and a deteriorating earnings outlook1, I would not chase the equity market rally here. It’s positive that the global economy is not imploding as some suggested it might. But I think there are still shoes to drop once lagged effect of higher US interest rates kick in.
Large language model battles heat up
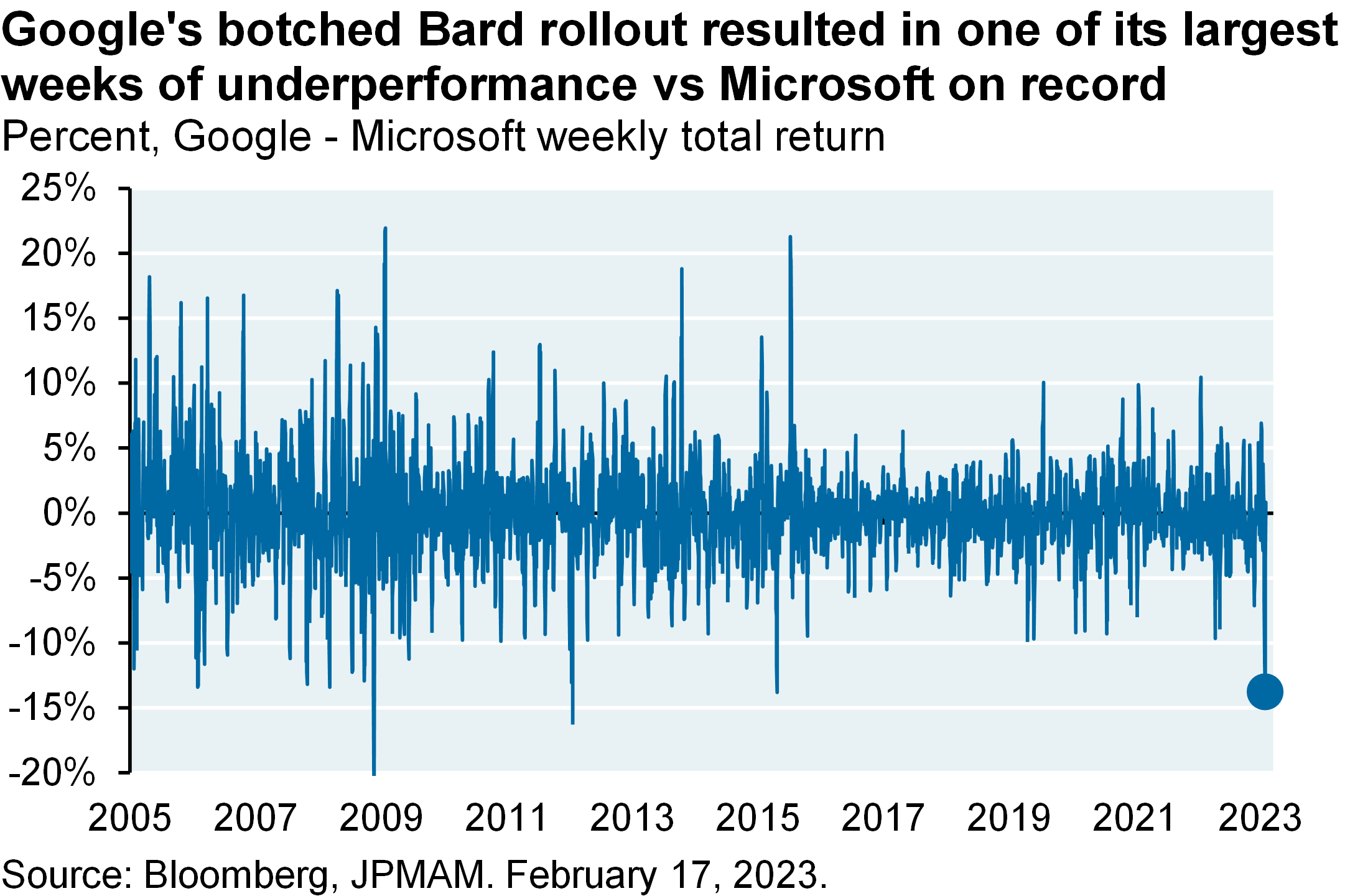
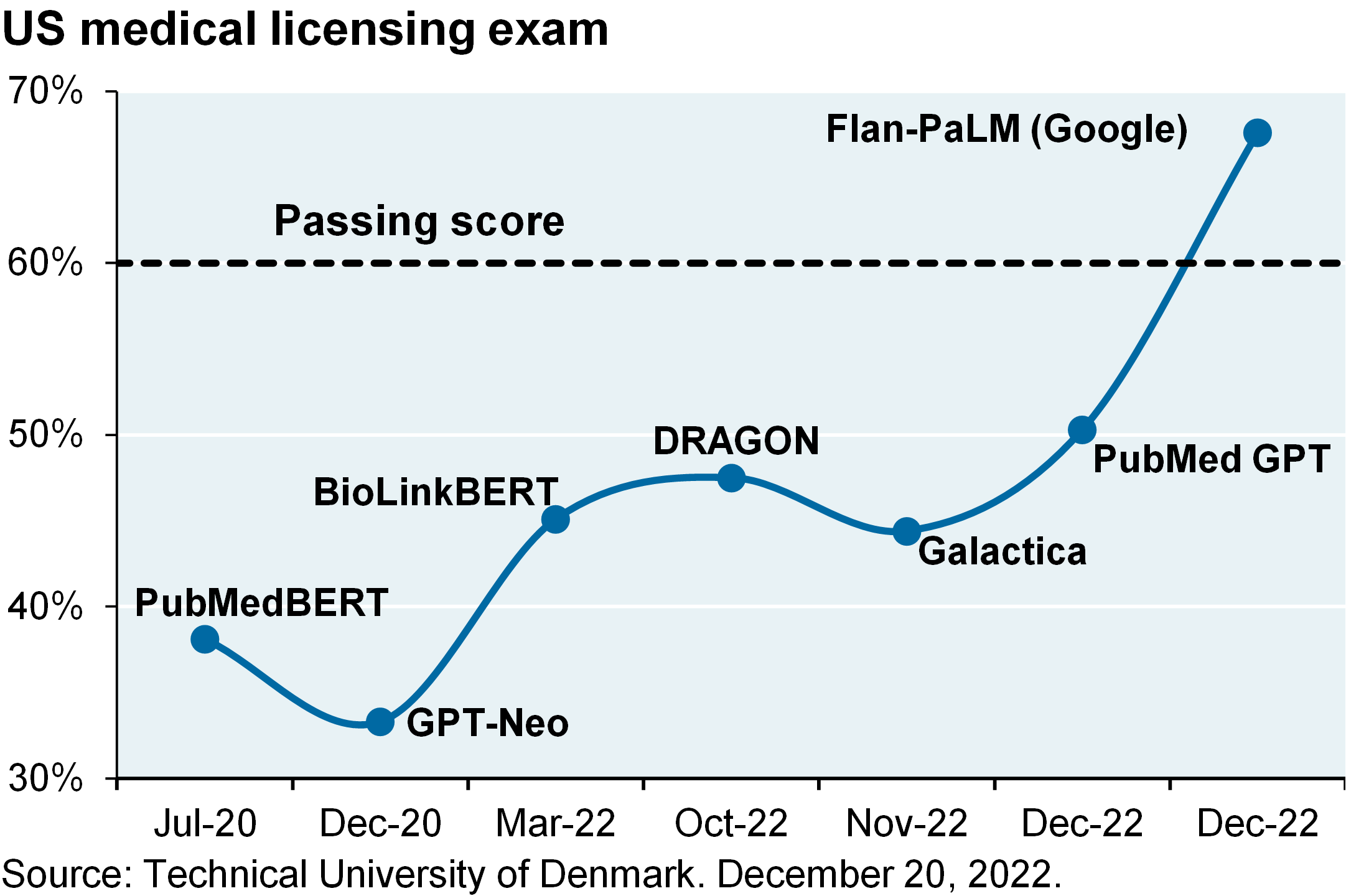
I was at our annual conference in Miami two weeks ago listening to Sam Altman from OpenAI talk about ChatGPT on the same day that Google rolled out Bard, its own large language model (LLM). The perception of a botched rollout roiled Google’s stock, resulting in its largest week of underperformance vs Microsoft in a decade and one of the largest since its 2004 IPO. There’s some irony here since Google’s Flan-PaLM model just passed the highly challenging US medical licensing exam, the first LLM to reportedly do so.
Some big picture thoughts on LLM:
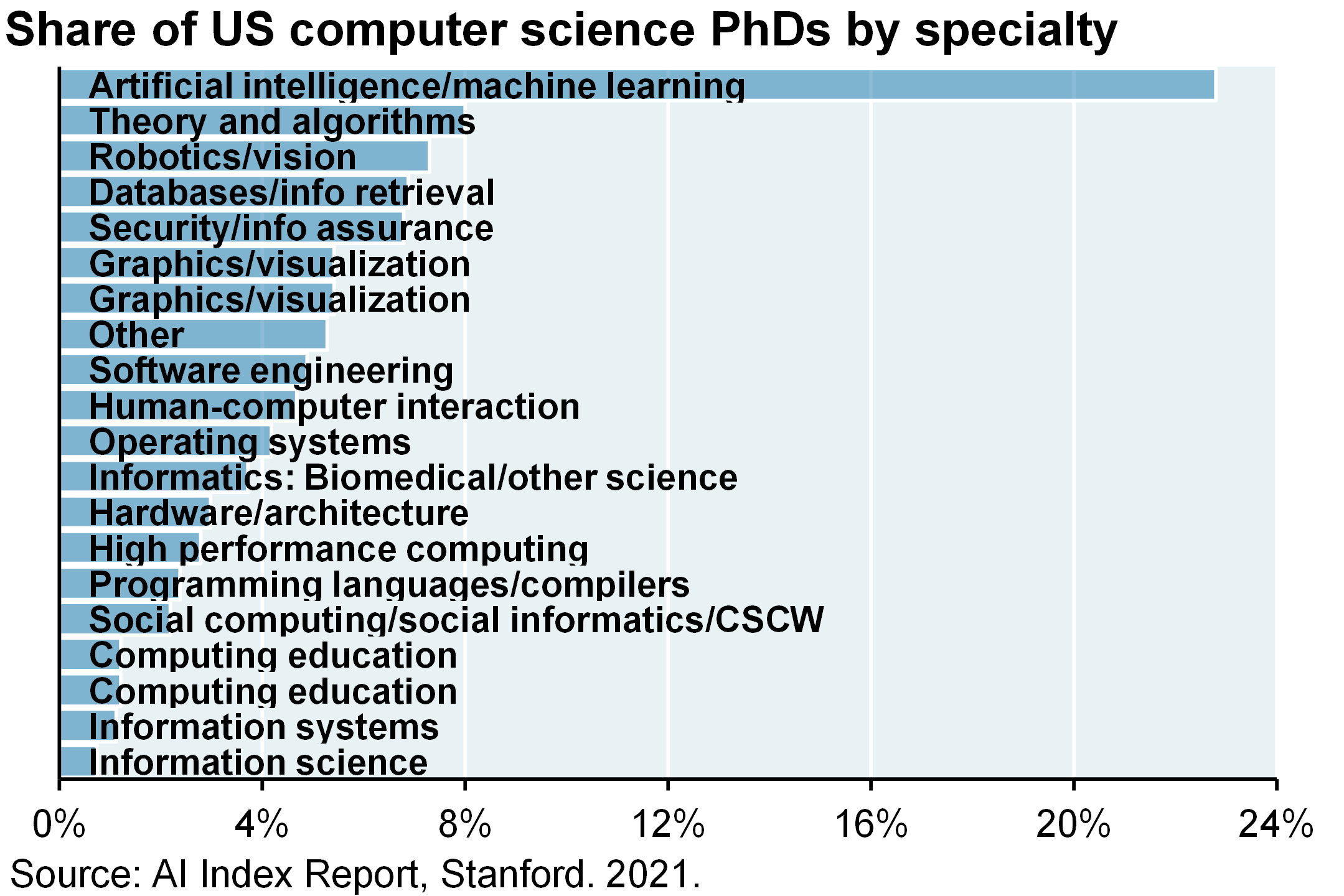
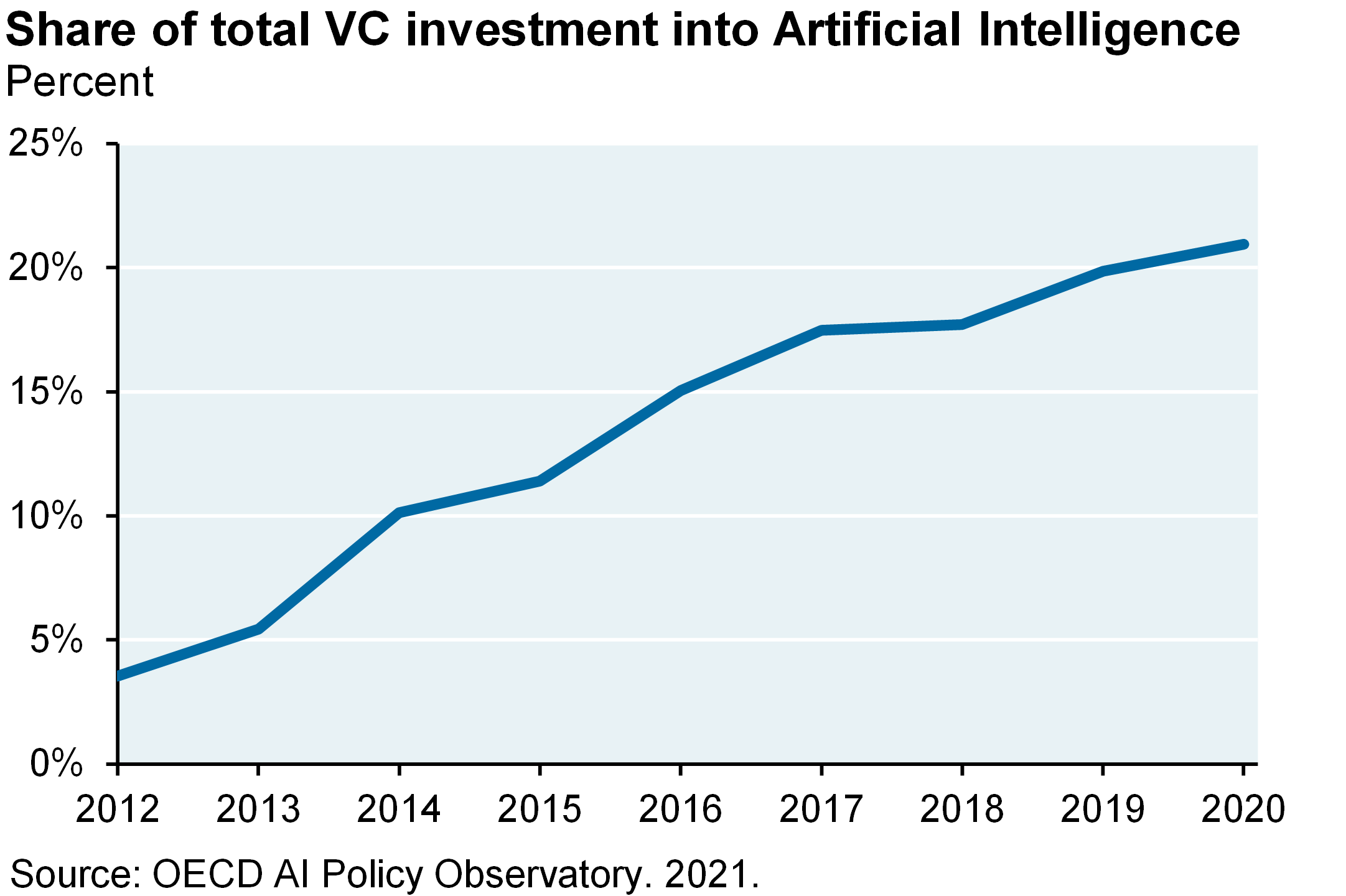
- Artificial intelligence is attracting a lot of VC money and mind-share among computer scientists, as shown below. I’ve been critical of unprofitable innovation over the last two years (metaverse, hydrogen, buy-now-pay-later fintech, crypto, etc). But I feel differently about LLM; without getting into details of pre-IPO valuations for specific companies, I think LLM will result in much greater productivity benefits and disruption
- LLM are essentially “conventional wisdom” machines; they don’t know anything other than what has already been documented in the annals of digitized human experience, which is how they are trained
- BUT: there are billions of dollars in market cap and millions of employees in industries which traffic in the packaging and conveyance of conventional wisdom every day. In a 2022 survey of natural language processing researchers, 73% believed that “labor automation from artificial intelligence could plausibly lead to revolutionary societal change in this century, on at least the scale of the Industrial Revolution”2
But before we get too carried away, let’s acknowledge the shortcomings of LLM as they exist right now…
Hallucinations, bears in space and porcelain: LLM still make a lot of mistakes despite all the training
- ChatGPT reportedly has a 147 IQ (99.9th percentile)3, but LLM need to get better since they routinely make mistakes called “hallucinations”. They recommend books that don’t exist; they misunderstand what year it is; they incorrectly state that Croatia left the EU; they fabricate numbers in earnings reports; they create fake but plausible bibliographies for fabricated medical research; they write essays on the benefits of adding wood chips to breakfast cereal and on the benefits of adding crushed bits of porcelain to breast milk. The list of such examples is endless4, leading some AI researchers to describe LLM as “stochastic parrots”
- Galactica, another LLM roll-out failure: Meta’s LLM Galactica was yanked last November after just three days when its science-oriented model was criticized as “statistical nonsense at scale” and “dangerous”5. Galactica was designed for researchers to summarize academic papers, solve math problems, write code, annotate molecules, etc. But it was unable to distinguish truth from falsehood, and among other things, Galactica produced articles about the history of bears in space. Gary Marcus, emeritus professor of neural networks at NYU and founder of a machine learning company, described Galactica as “pitch perfect and utterly bogus imitations of science and math, presented as the real thing”6
- Stack Overflow, a question-and-answer site many programmers use, imposed a temporary ban on ChatGPT-generated submissions: “Overall, because the average rate of getting correct answers from ChatGPT is too low, the posting of answers created by ChatGPT is substantially harmful to the site and to users who are asking or looking for correct answers”7
- New products will be needed to identify nonsense LLM output. Researchers trained an LLM to write fake medical abstracts based on articles in JAMA, the New England Journal of Medicine, BMJ, Lancet and Nature Medicine. An AI-output checker was only able to identify 2/3 of the fakes, and human reviewers weren’t able to do much better; humans also mistakenly described 15% of the real ones as being fake8
- The new Bing chatbot has already been “jailbroken” to provide advice on how to rob a bank, burglarize a house and hot-wire a car (by Jensen Harris, ex-Microsoft / currently at Textio)
- The ability for AI to replace humans is sometimes exaggerated. In 2016, a preeminent deep learning expert predicted the end of the radiology profession, advocating that hospitals stop training them since within 5 years, deep learning would be better9. The consensus today: machine learning for radiology is harder than it looks10, and AI is best used complementing humans instead
- LLM have begun to train themselves to get better. Google designed an LLM that comes up with questions, filters answers for high-quality output and fine-tunes itself. This led to improved performance on various language tasks (from 74% to 82% on one benchmark, and from 78% to 83% on another)11. Human interaction is also a part of the improvement process; the “.5” in Chat-GPT 3.5 refers to the incorporation of human feedback12 that was consequential enough to give it another digit
Even with all the hallucinations, LLM are making progress on certain well-specified tasks. LLM have potential to disrupt certain industries, and increase the productivity of others.
- Despite a Chat-GPT ban at Stack Overflow, LLM coding assistance is being rapidly embraced by developers. GitHub’s Copilot tool which is powered by OpenAI added 400k users in its first month, and now has over 1 million users who use it for ~40% of the code in their projects13. Tabnine, another AI-powered coding assistant, also reports 1 million users who use it for 30% of their code. Microsoft has an advantage here through its partnership with OpenAI and its ownership of GitHub
- LLMs have outperformed sell-side analysts when picking stocks (not shocking)14, and show promise regarding long-short trading strategies based on synthesis of CFO conference call transcripts15. They also improve audit quality using frequency of restatements as a proxy, and do so with fewer people16. Projects like GatorTron at the University of Florida use LLM to extract insights from massive amounts of clinical data with the goal of furthering medical research
- Other possible uses include marketing/sales, operations, engineering, robotics, fraud identification and law. Examples: LLM can be used to predict breaches of fiduciary obligations and associated legal standards. A database of court opinions on breach of fiduciary duty has never been online for LLM to train on17. Even so, GPT-3.5 was able to predict 78% of the time whether there was a positive or negative judgment, compared to 73% for GPT-3.0 and 27% for OpenAI’s 2020 LLM. LLM using GPT-3.5 achieved 50% on the Multistate Bar Exam (vs a 25% baseline guessing rate), and passed Evidence and Torts18. ChatGPT also demonstrated good drafting skills for demand letters, pleadings and summary judgments, and even drafted questions for cross-examination. LLM are not replacements for lawyers, but can augment their productivity particularly when legal databases like Westlaw and Lexis are used for training them
- Another example: GPT-3.5 as corporate lobbyist aide. An AI model was fed a list of legislation, estimated which bills were relevant to different companies and drafted letters to bill sponsors arguing for relevant changes to it19. The model had an 80% chance of identifying whether a bill was relevant to each company
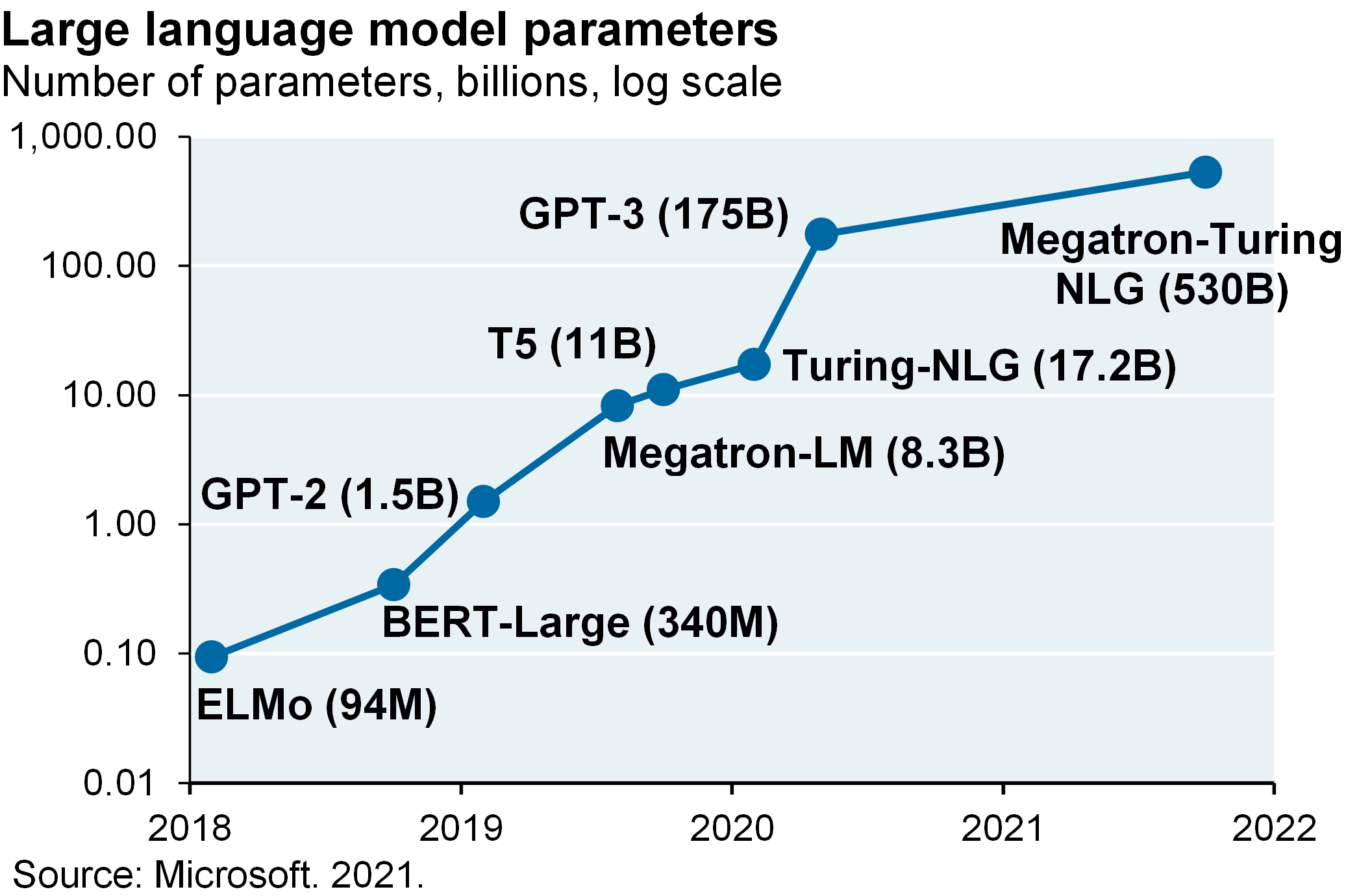
- Microsoft and NVIDIA have released Megatron, the largest LLM to date with 530 billion parameters and which aims to let businesses create their own AI applications
Is there an upper limit regarding online information to train these models?
AI researchers estimate that the stock of high-quality language data is between 4.6 trillion and 17 trillion words, which is less than one order of magnitude larger than the largest datasets used today. They believe that LLM will exhaust high-quality data between 2023 and 2027, while the stock of low-quality data and images will last well beyond that.
Source: “Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning”, Sevilla (University of Aberdeen) et al, October 2022
What will happen to the profitability of the search business?
- Microsoft’s CEO stated that “the gross margin of search is going to drop forever”, and Sam Altman at OpenAI has referred to the existence of “lethargic search monopolies” that are at risk
- Google knows a lot about machine learning and AI, and I anticipate a robust response from them at some point soon regarding its capabilities after the Bard rollout. But future search economics do look more challenging. Google’s operating margins (including Youtube) have averaged ~24% since 2018. Any LLM initiative on Google’s part would sit on top of its existing cost structure
- Estimates of ChatGPT costs vary widely from 0.4 - 4.5 cents per query, a function of the number of words generated per query, model size20 and costs of computing21. Let’s assume 2 cents per ChatGPT query as a rough midpoint. This compares to 0.2 - 0.3 cents of infrastructure costs per standard Google search query. Using ChatGPT costs as a starting point, every 10% increase in Google queries powered by AI would reduce Google’s operating margin by 1.5%-1.7%, according to the Morgan Stanley reports cited below. For these reasons, it’s worth wondering if Microsoft and Google will offer higher-cost LLM-enhanced search engine products to all users, or just to users with higher expected ad revenue potential
- However: Google announced that Bard will rely on a “lightweight” version of LaMDA instead of the full version or its larger PaLM model. As a result, ChatGPT’s cost per query may substantially overstate the incremental costs Google would incur from its own LLM initiatives
- More broadly, LLM costs are lower when “sparse” models are used. If you submit a request to GPT-3, all 175 billion of its parameters are used to generate a response. Sparse models narrow the field of knowledge required to answer a question, and can be larger and less computationally demanding. GLaM, a sparse expert model developed by Google, is 7x larger than GPT-3, requires two-thirds less energy to train, requires half as much computing effort and outperforms GPT-3 on a wide range of natural language tasks22
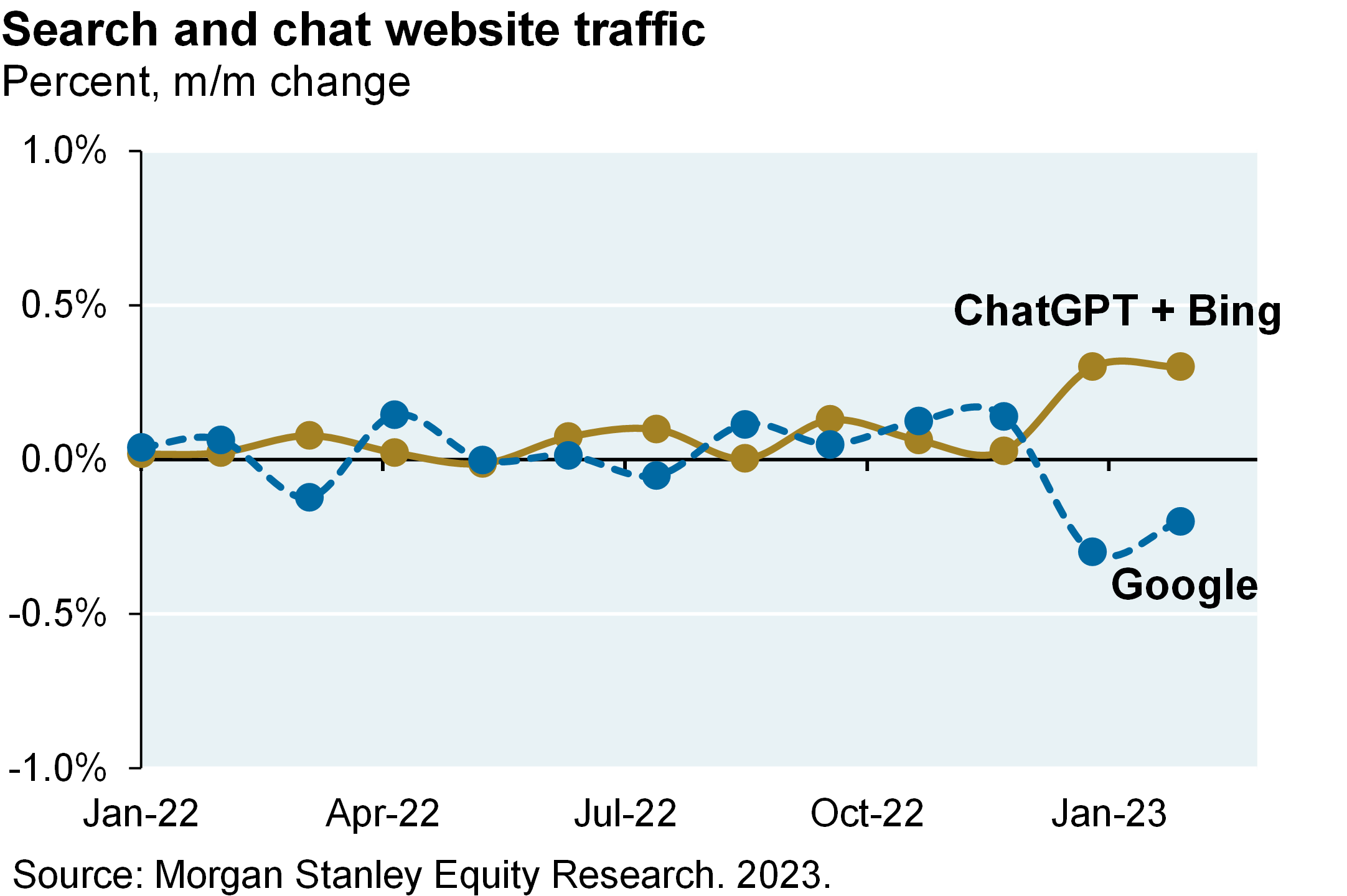
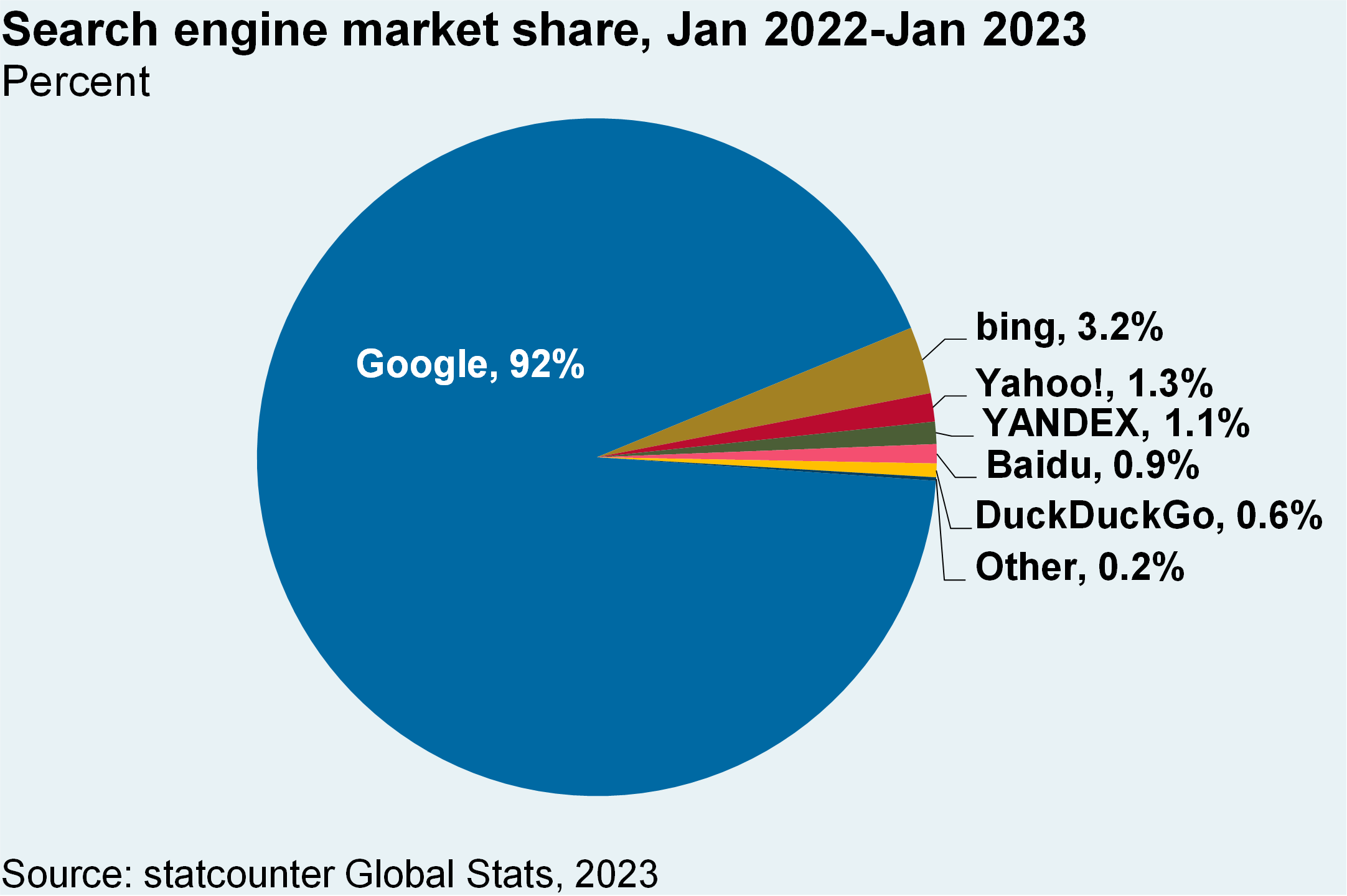
- Google’s share of search traffic has averaged 92% over the last year. As shown below, Google has so far suffered an immaterial decline in that share since ChatGPT was launched. These relative shares also imply that Google’s LLM could get smarter a lot faster than ChatGPT due to more usage
What is the future of LLM capabilities? Watch the “Big Bench”
There’s a project underway called “Big Bench” with contributions from Google, OpenAI and over 100 other AI firms. Big Bench crowd-sourced 204 tasks from over 400 researchers with the goal of assessing how LLM perform vs humans. From the authors: “Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG Bench focuses on tasks believed to be beyond the capabilities of current language models”. The tasks are interesting, and I list indicative ones below23.
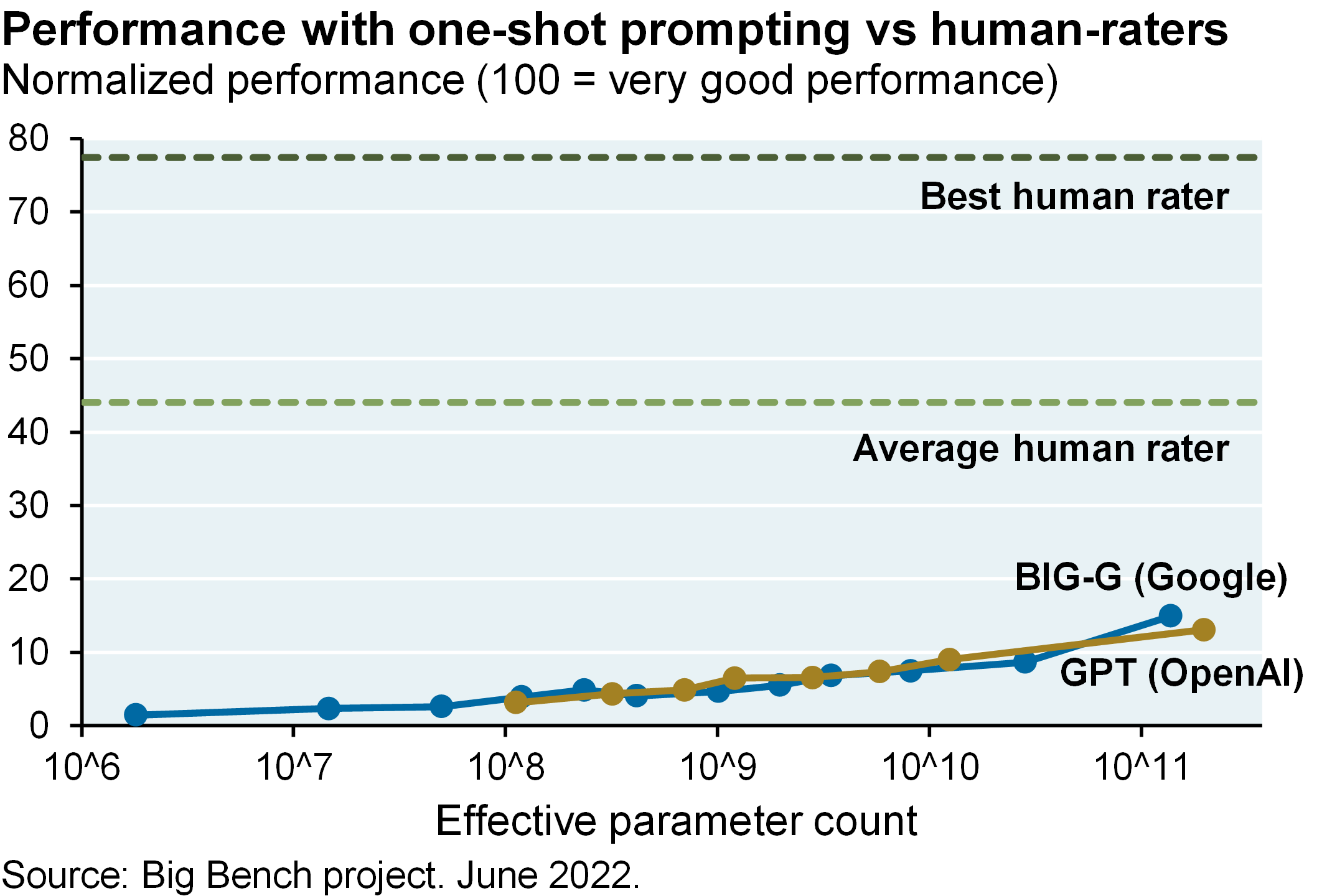
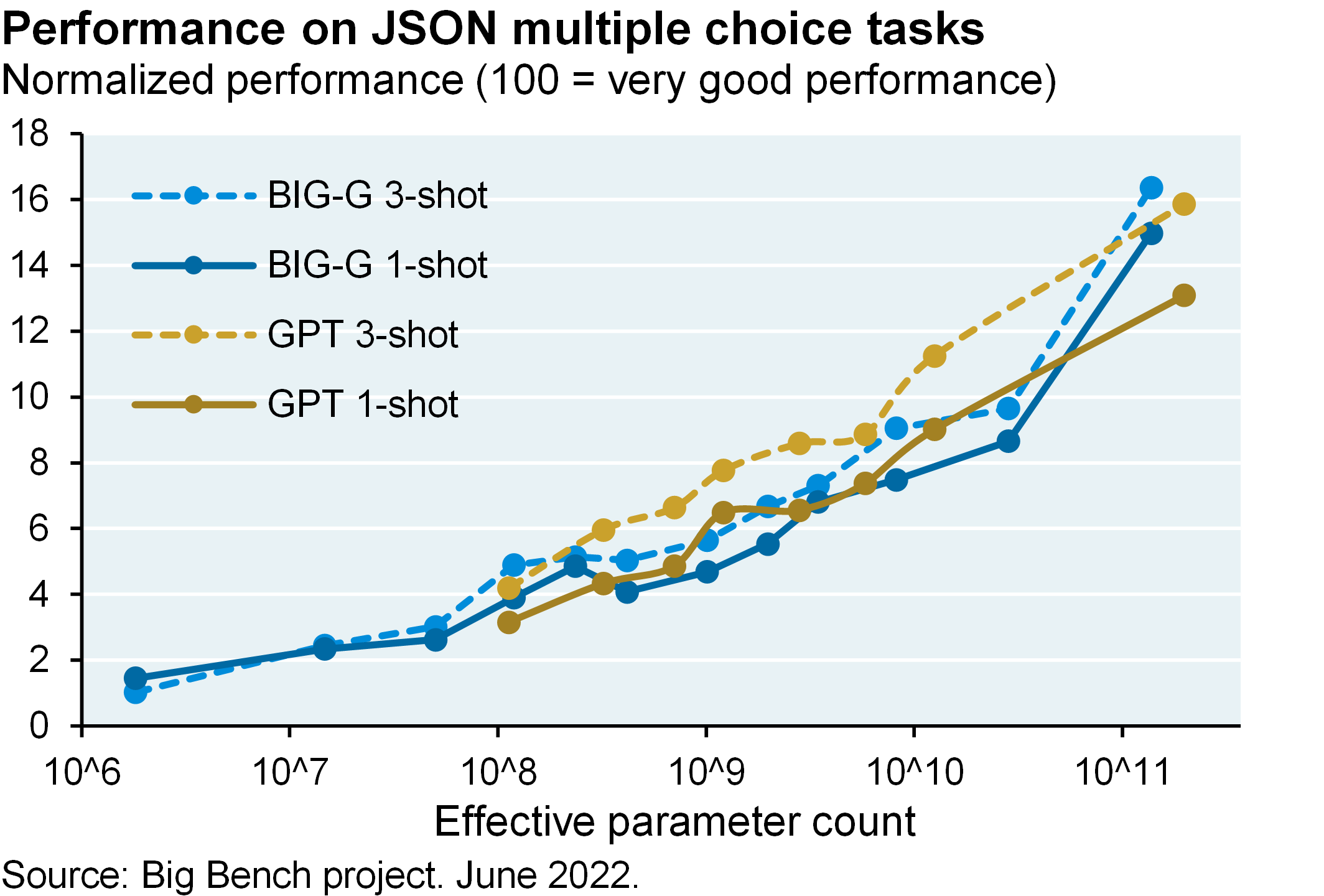
The Big Bench team published their first results last summer and as shown below, there’s a way to go before LLM catch up to humans on higher degree-of-difficulty tasks. Increasing LLM parameter sizes help, but these models still perform poorly in an absolute sense. Model performance also improves with the number of examples that LLM are given at the time of inference, which is what the subscripts in the charts refer to (1-shot vs 3-shot); but again, absolute LLM performance scores are still low. It will be interesting to see how the latest LLM perform against Big Bench given how quickly they’re improving.
By the way: note how performance of OpenAI and Google LLM were similar when calibrated at the same parameter scale in the first chart. The LLM battles are just beginning. Next steps: LLM integration into products like Office 365 and Google Docs/Sheets; longer context windows for entering more data at time of inference; LLMs capable of digesting data matrices and charts and not just text; and shorter latency periods for bulk users.
Indicative Big Bench challenges:
- Ask models to determine whether a given text is intended to be a joke (with dark humor) or not
- Give an English language description of Python code
- Solve logic grid puzzles and identify logical fallacies
- Classify CIFAR10 images encoded in various ways
- Find a move in the chess position resulting in checkmate
- Ask a model to guess popular movies from their plot descriptions written in emojis
- Answer questions in Spanish about cryobiology
- GRE exam reading comprehension
- A set of shapes is given in simple language; determine the number of intersection points between shapes
- Given short crime stories, identify the perpetrator and explain the reasoning
- Present models with a proverb in English and ask it to choose a proverb in Russian that is closest in meaning
- Ask one instance of a model to teach another instance, and then evaluate the quality
- Identify which ethical choice best aligns with human judgement
- Determine which of two sentences is sarcastic
1 Since the close of the Q4 earnings seasons, EPS estimates have fallen by -1.7% vs an average increase of +2.8%. This is the largest decline in 24 years outside of the 2001 recession, the financial crisis and the initial pandemic quarter. [Credit Suisse, Feb 13, 2023]
2 “What Do NLP Researchers Believe? NLP Community Metasurvey,” Michael et al, Cornell, August 2022
3 “Language models and cognitive automation for economic research”, Anton Korinek, UVA, Feb 2023
4 “Deep learning is hitting a wall”, Nautilus, Gary Marcus, March 2022
5 Quotes from Grady Booch (developer of the Unified Modeling Language) and Michael Black (Director of the Max Planck Institute for Intelligent Systems)
6 “A few words about bullsh*t”, Gary Marcus, November 15, 2022
7 “Temporary policy: ChatGPT is banned”, Stackoverflow.com, December 5, 2022
8 “Abstracts written by ChatGPT fool scientists”, Nature, Jan 12, 2023
9 “AI Platforms like ChatGPT Are Easy to Use but Potentially Dangerous”, G. Marcus, Scientific American, Dec 2022
10 “How I failed machine learning in medical imaging – shortcomings and recommendations”, G. Varoquaux, National Institute for Research in Digital Science and Technology (France), May 2022
11 “Large language models can self-improve”, Hou et al (Google), October 2022
12 The relevant acronym is “reinforcement learning with human feedback”, or RLHF
13 “GitHub's AI-assisted Copilot writes code for you, but is it legal or ethical?”, ZDnet.com, July 8, 2022
14 “Human Versus Machine: Robo-Analyst vs Traditional Research Recommendations”, Pacelli (HBS), June 2022
15 “Generating Alpha using NLP Insights and Machine Learning”, Chris Kantos (CFA-UK), Sep 12, 2022
16 “Is artificial intelligence improving the audit process?”, Review of Accounting Studies, Fedyk et al, July 2022
17 “Large language models as fiduciaries”, J. Nay, Stanford University Center for Legal Informatics, Jan 2023
18 “GPT takes the bar exam”, Bommarito et al, Stanford University Center for Legal Informatics, Jan 2023
19 “Large language models as corporate lobbyists”, J. Nay, Stanford University, Jan 2023
20 GPT-4 is rumored to have its parameters increase from 175 billion to 1 trillion
21 “Are Google’s margins at risk from ChatGPT and OpenAI?” (Jan 10, 2023) and “How large are the incremental AI costs” (Feb 9, 2023), Brian Nowak, Morgan Stanley Equity Research. MS believes that OpenAI is losing money on its third party developer licensing arrangements for ChatGPT; it will be interesting to see whether Google undercuts OpenAI on pricing of its own natural language developer tools when they’re released
22 “The Next Generation of Large Language Models”, Rob Toews (Radical Ventures), February 7, 2023
23 “Beyond the imitation game: quantifying and extrapolating the capabilities of language models”, June 2022
IMPORTANT INFORMATION
This report uses rigorous security protocols for selected data sourced from Chase credit and debit card transactions to ensure all information is kept confidential and secure. All selected data is highly aggregated and all unique identifiable information, including names, account numbers, addresses, dates of birth, and Social Security Numbers, is removed from the data before the report’s author receives it. The data in this report is not representative of Chase’s overall credit and debit cardholder population.
The views, opinions and estimates expressed herein constitute Michael Cembalest’s judgment based on current market conditions and are subject to change without notice. Information herein may differ from those expressed by other areas of J.P. Morgan. This information in no way constitutes J.P. Morgan Research and should not be treated as such.
The views contained herein are not to be taken as advice or a recommendation to buy or sell any investment in any jurisdiction, nor is it a commitment from J.P. Morgan or any of its subsidiaries to participate in any of the transactions mentioned herein. Any forecasts, figures, opinions or investment techniques and strategies set out are for information purposes only, based on certain assumptions and current market conditions and are subject to change without prior notice. All information presented herein is considered to be accurate at the time of production. This material does not contain sufficient information to support an investment decision and it should not be relied upon by you in evaluating the merits of investing in any securities or products. In addition, users should make an independent assessment of the legal, regulatory, tax, credit and accounting implications and determine, together with their own professional advisers, if any investment mentioned herein is believed to be suitable to their personal goals. Investors should ensure that they obtain all available relevant information before making any investment. It should be noted that investment involves risks, the value of investments and the income from them may fluctuate in accordance with market conditions and taxation agreements and investors may not get back the full amount invested. Both past performance and yields are not reliable indicators of current and future results.
Non-affiliated entities mentioned are for informational purposes only and should not be construed as an endorsement or sponsorship of J.P. Morgan Chase & Co. or its affiliates.
For J.P. Morgan Asset Management Clients:
J.P. Morgan Asset Management is the brand for the asset management business of JPMorgan Chase & Co. and its affiliates worldwide.
To the extent permitted by applicable law, we may record telephone calls and monitor electronic communications to comply with our legal and regulatory obligations and internal policies. Personal data will be collected, stored and processed by J.P. Morgan Asset Management in accordance with our privacy policies at https://am.jpmorgan.com/global/privacy.
ACCESSIBILITY
For U.S. only: If you are a person with a disability and need additional support in viewing the material, please call us at 1-800-343-1113 for assistance.
This communication is issued by the following entities:
In the United States, by J.P. Morgan Investment Management Inc. or J.P. Morgan Alternative Asset Management, Inc., both regulated by the Securities and Exchange Commission; in Latin America, for intended recipients’ use only, by local J.P. Morgan entities, as the case may be.; in Canada, for institutional clients’ use only, by JPMorgan Asset Management (Canada) Inc., which is a registered Portfolio Manager and Exempt Market Dealer in all Canadian provinces and territories except the Yukon and is also registered as an Investment Fund Manager in British Columbia, Ontario, Quebec and Newfoundland and Labrador. In the United Kingdom, by JPMorgan Asset Management (UK) Limited, which is authorized and regulated by the Financial Conduct Authority; in other European jurisdictions, by JPMorgan Asset Management (Europe) S.à r.l. In Asia Pacific (“APAC”), by the following issuing entities and in the respective jurisdictions in which they are primarily regulated: JPMorgan Asset Management (Asia Pacific) Limited, or JPMorgan Funds (Asia) Limited, or JPMorgan Asset Management Real Assets (Asia) Limited, each of which is regulated by the Securities and Futures Commission of Hong Kong; JPMorgan Asset Management (Singapore) Limited (Co. Reg. No. 197601586K), which this advertisement or publication has not been reviewed by the Monetary Authority of Singapore; JPMorgan Asset Management (Taiwan) Limited; JPMorgan Asset Management (Japan) Limited, which is a member of the Investment Trusts Association, Japan, the Japan Investment Advisers Association, Type II Financial Instruments Firms Association and the Japan Securities Dealers Association and is regulated by the Financial Services Agency (registration number “Kanto Local Finance Bureau (Financial Instruments Firm) No. 330”); in Australia, to wholesale clients only as defined in section 761A and 761G of the Corporations Act 2001 (Commonwealth), by JPMorgan Asset Management (Australia) Limited (ABN 55143832080) (AFSL 376919). For all other markets in APAC, to intended recipients only.
For J.P. Morgan Private Bank Clients:
ACCESSIBILITY
J.P. Morgan is committed to making our products and services accessible to meet the financial services needs of all our clients. Please direct any accessibility issues to the Private Bank Client Service Center at 1-866-265-1727.
LEGAL ENTITY, BRAND & REGULATORY INFORMATION
In the United States, bank deposit accounts and related services, such as checking, savings and bank lending, are offered by JPMorgan Chase Bank, N.A. Member FDIC.
JPMorgan Chase Bank, N.A. and its affiliates (collectively “JPMCB”) offer investment products, which may include bank-managed investment accounts and custody, as part of its trust and fiduciary services. Other investment products and services, such as brokerage and advisory accounts, are offered through J.P. Morgan Securities LLC (“JPMS”), a member of FINRA and SIPC. Annuities are made available through Chase Insurance Agency, Inc. (CIA), a licensed insurance agency, doing business as Chase Insurance Agency Services, Inc. in Florida. JPMCB, JPMS and CIA are affiliated companies under the common control of JPM. Products not available in all states.
In Germany, this material is issued by J.P. Morgan SE, with its registered office at Taunustor 1 (TaunusTurm), 60310 Frankfurt am Main, Germany, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB). In Luxembourg, this material is issued by J.P. Morgan SE – Luxembourg Branch, with registered office at European Bank and Business Centre, 6 route de Treves, L-2633, Senningerberg, Luxembourg, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – Luxembourg Branch is also supervised by the Commission de Surveillance du Secteur Financier (CSSF); registered under R.C.S Luxembourg B255938. In the United Kingdom, this material is issued by J.P. Morgan SE – London Branch, registered office at 25 Bank Street, Canary Wharf, London E14 5JP, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – London Branch is also supervised by the Financial Conduct Authority and Prudential Regulation Authority. In Spain, this material is distributed by J.P. Morgan SE, Sucursal en España, with registered office at Paseo de la Castellana, 31, 28046 Madrid, Spain, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE, Sucursal en España is also supervised by the Spanish Securities Market Commission (CNMV); registered with Bank of Spain as a branch of J.P. Morgan SE under code 1567. In Italy, this material is distributed by J.P. Morgan SE – Milan Branch, with its registered office at Via Cordusio, n.3, Milan 20123, Italy, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – Milan Branch is also supervised by Bank of Italy and the Commissione Nazionale per le Società e la Borsa (CONSOB); registered with Bank of Italy as a branch of J.P. Morgan SE under code 8076; Milan Chamber of Commerce Registered Number: REA MI 2536325. In the Netherlands, this material is distributed by J.P. Morgan SE – Amsterdam Branch, with registered office at World Trade Centre, Tower B, Strawinskylaan 1135, 1077 XX, Amsterdam, The Netherlands, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – Amsterdam Branch is also supervised by De Nederlandsche Bank (DNB) and the Autoriteit Financiële Markten (AFM) in the Netherlands. Registered with the Kamer van Koophandel as a branch of J.P. Morgan SE under registration number 72610220. In Denmark, this material is distributed by J.P. Morgan SE – Copenhagen Branch, filial af J.P. Morgan SE, Tyskland, with registered office at Kalvebod Brygge 39-41, 1560 København V, Denmark, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – Copenhagen Branch, filial af J.P. Morgan SE, Tyskland is also supervised by Finanstilsynet (Danish FSA) and is registered with Finanstilsynet as a branch of J.P. Morgan SE under code 29010. In Sweden, this material is distributed by J.P. Morgan SE – Stockholm Bankfilial, with registered office at Hamngatan 15, Stockholm, 11147, Sweden, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – Stockholm Bankfilial is also supervised by Finansinspektionen (Swedish FSA); registered with Finansinspektionen as a branch of J.P. Morgan SE. In France, this material is distributed by JPMCB, Paris branch, which is regulated by the French banking authorities Autorité de Contrôle Prudentiel et de Résolution and Autorité des Marchés Financiers. In Switzerland, this material is distributed by J.P. Morgan (Suisse) SA, with registered address at rue de la Confédération, 8, 1211, Geneva, Switzerland, which is authorised and supervised by the Swiss Financial Market Supervisory Authority (FINMA), as a bank and a securities dealer in Switzerland. Please consult the following link to obtain information regarding J.P. Morgan’s EMEA data protection policy: https://www.jpmorgan.com/privacy.
In Hong Kong, this material is distributed by JPMCB, Hong Kong branch. JPMCB, Hong Kong branch is regulated by the Hong Kong Monetary Authority and the Securities and Futures Commission of Hong Kong. In Hong Kong, we will cease to use your personal data for our marketing purposes without charge if you so request. In Singapore, this material is distributed by JPMCB, Singapore branch. JPMCB, Singapore branch is regulated by the Monetary Authority of Singapore. Dealing and advisory services and discretionary investment management services are provided to you by JPMCB, Hong Kong/Singapore branch (as notified to you). Banking and custody services are provided to you by JPMCB Singapore Branch. The contents of this document have not been reviewed by any regulatory authority in Hong Kong, Singapore or any other jurisdictions. You are advised to exercise caution in relation to this document. If you are in any doubt about any of the contents of this document, you should obtain independent professional advice. For materials which constitute product advertisement under the Securities and Futures Act and the Financial Advisers Act, this advertisement has not been reviewed by the Monetary Authority of Singapore. JPMorgan Chase Bank, N.A. is a national banking association chartered under the laws of the United States, and as a body corporate, its shareholder’s liability is limited.
With respect to countries in Latin America, the distribution of this material may be restricted in certain jurisdictions. We may offer and/or sell to you securities or other financial instruments which may not be registered under, and are not the subject of a public offering under, the securities or other financial regulatory laws of your home country. Such securities or instruments are offered and/or sold to you on a private basis only. Any communication by us to you regarding such securities or instruments, including without limitation the delivery of a prospectus, term sheet or other offering document, is not intended by us as an offer to sell or a solicitation of an offer to buy any securities or instruments in any jurisdiction in which such an offer or a solicitation is unlawful. Furthermore, such securities or instruments may be subject to certain regulatory and/or contractual restrictions on subsequent transfer by you, and you are solely responsible for ascertaining and complying with such restrictions. To the extent this content makes reference to a fund, the Fund may not be publicly offered in any Latin American country, without previous registration of such fund’s securities in compliance with the laws of the corresponding jurisdiction. Public offering of any security, including the shares of the Fund, without previous registration at Brazilian Securities and Exchange Commission— CVM is completely prohibited. Some products or services contained in the materials might not be currently provided by the Brazilian and Mexican platforms.
JPMorgan Chase Bank, N.A. (JPMCBNA) (ABN 43 074 112 011/AFS Licence No: 238367) is regulated by the Australian Securities and Investment Commission and the Australian Prudential Regulation Authority. Material provided by JPMCBNA in Australia is to “wholesale clients” only. For the purposes of this paragraph the term “wholesale client” has the meaning given in section 761G of the Corporations Act 2001 (Cth). Please inform us if you are not a Wholesale Client now or if you cease to be a Wholesale Client at any time in the future.
JPMS is a registered foreign company (overseas) (ARBN 109293610) incorporated in Delaware, U.S.A. Under Australian financial services licensing requirements, carrying on a financial services business in Australia requires a financial service provider, such as J.P. Morgan Securities LLC (JPMS), to hold an Australian Financial Services Licence (AFSL), unless an exemption applies. JPMS is exempt from the requirement to hold an AFSL under the Corporations Act 2001 (Cth) (Act) in respect of financial services it provides to you, and is regulated by the SEC, FINRA and CFTC under U.S. laws, which differ from Australian laws. Material provided by JPMS in Australia is to “wholesale clients” only. The information provided in this material is not intended to be, and must not be, distributed or passed on, directly or indirectly, to any other class of persons in Australia. For the purposes of this paragraph the term “wholesale client” has the meaning given in section 761G of the Act. Please inform us immediately if you are not a Wholesale Client now or if you cease to be a Wholesale Client at any time in the future.
This material has not been prepared specifically for Australian investors. It:
May contain references to dollar amounts which are not Australian dollars;
May contain financial information which is not prepared in accordance with Australian law or practices;
May not address risks associated with investment in foreign currency denominated investments; and
Does not address Australian tax issues.
Winter Heating
US economy stays warm, large language model battles get hot
[START RECORDING]
FEMALE VOICE: This podcast has been prepared exclusively for institutional wholesale professional clients and qualified investors only as defined by local laws and regulations. Please read other important information, which can be found on the link at the end of the podcast episode.
MR. MICHAEL CEMBALEST: Welcome to the February 2023 Eye on the Market podcast. This one is called Winter Heating. Most of what we’re going to be talking about are the battles between the new large language models, which you’re reading about everywhere, a quick few comments on the markets and the Fed. One of the warmest northern hemisphere winters in decades has coincided with a flurry of positive economic surprises in the U.S., Europe, and Japan. The U.S. list of positive surprises is a long line, from employment, retail sales, manufacturing, jobless claims, a miniscule high-yield default rate, capital spending projections are stable, et cetera, so definitely a surprise in terms of how strong the U.S. economy is in January and February.
The problem is that policy rates aren’t normalized yet, and looks like we may peak closer to 5 and a quarter to 550 on the funds rate before the Fed pauses. So we still see some weakness ahead in our preferred leading indicator, which is looking at new orders versus inventories. And the bottom line is it looks like we’ve got two to three more Fed hikes ahead and a mild recession whose likelihood and possible severity is probably shrinking.
What makes us not really want to chase the equity market rally here is that the rally so far this year has been based, at least in part, on appreciation of some low-quality and high-short-interest stocks, a huge explosion in the money supply both in Asia, and the view that the Fed hikes aren’t going to do that much damage to the economy, which I think is still flowing through.
We did not have the view there was going to be a severe recession this year; we thought it would be a mild one. And we still think that’s the case. And as we’re looking at leading indicators for earnings, it does look like there is some downside for both earnings and margins in the month ahead, but nothing too catastrophic.
The centerpiece of today’s podcast and our Eye on the Market this week is on these large language models, which have been impossible to ignore over the last couple months. I was at our annual client investment conference in Miami a couple weeks ago was listening to Sam Altman from OpenAI talk about ChatGPT. And it was on the same day that Google had rolled out Bard, its own large language model, where there was a perception of a botched rollout by Google.
And it resulted in one of the largest weeks of underperformance of Google versus Microsoft in a decade and one of the largest since Google’s IPO in 2004, which was ironic because just last month, one of Google’s large language models passed the U.S. medical licensing exam for the first time. It was reportedly the first one of these models to be able to do that.
So I want to give you some big picture thoughts on all of this large language model stuff. Artificial intelligence is attracting a ton of VC money and mindshare among computer science Ph.Ds. I’ve been very critical of unprofitable innovation over the last couple of years, whether it was the metaverse or hydrogen or these buy now, pay later companies or crypto or anything. But I feel differently about this stuff without getting into the details of pre-IPO evaluations for specific companies. I think these models are going to result in greater productivity benefits and disruption than those other things, although the bar is admittedly low when you’re talking about things like metaverse and crypto.
Large language models are essentially conventional wisdom machines. They don’t know anything other than what has already been documented in digitized human experience. They are not artificial intelligence the way that you conceive of it in terms of it coming up with something new that hasn’t been thought of yet.
That said, there’s billions and billions of dollars of market cap in companies that traffic in the packaging and conveyance of conventional wisdom all the time. And so what is interesting is that artificial intelligence in these large language models aren’t likely to kind of break any new ground intellectually, but they have the potential to displace a lot of the conventional thinking and conventional wisdom companies that exist right now.
So before we get too carried away, I want to be clear about a few things. These models make tons of mistakes, tons of them. And some of them are kind of hysterical. They recommend books that don’t exist, they don’t know what year it is, they believe certain countries have left the EU and it hasn’t happened, they make up numbers in earnings reports, they write essays on the benefits of adding woodchips to your breakfast cereal. The list is endless, and some AI people describe these models as sarcastic parrots because all they’re just doing is repeating things that they see, and sometimes not correctly.
And remember, it was just last November when Facebook/Meta rolled out Galactica, which was a large language model designed to help researchers summarize academic papers and solve math problems and write code. It was unable to distinguish truth from falsehood. It produced articles about the history of bears in space and got yanked after three days of intense criticism from the scientific community.
As another sign of how far there is to go here, Stack Overflow, which some of you may have heard of, is a question-and-answer site that a lot of developers and programmers use, I’ve even used it to help me with some Visual Basic code, they put a ban on ChatGPT submissions at that website because the rate of getting correct answers from it wasn’t good enough.
And so we’re still in a world where there’s a lot of errors that come out of this stuff, and you can make it, you can make these models produce garbage. Some researchers at Northwestern trained a model to write fake medical research abstracts, which both other models and humans couldn’t figure out were fake.
There’s also a lot of hype in this space. One of the grandfathers of machine learning in 2016 advised hospitals to stop training radiologists because we wouldn’t need them anymore since deep learning would be better. And here we are a few years later, and it turns out machine learning for radiology is a lot harder than it looks. And artificial intelligence in that kind of thing is best used when complementing doctors instead of replacing them. All of these errors and bizarre things that large language models do are referred to as hallucinations, and you can see why.
Now with that, these models are making progress on a lot of well-specified tasks. And despite what Stack Overflow to ChatGPT, there are a couple of new companies that are being rapidly embraced by developers. GitHub has something called a copilot tool, added 400,000 users in its first month, now has over a million users who use it to help them with 40% of their code. Tabnine is another artificial intelligence-powered coding assistant backed by a lot of the who’s who in Silicon Valley, also have a million users. And Microsoft has an advantage here, ‘cause it’s got a partnership with both OpenAI and it owns GitHub.
And there have been just in the last few months some interesting practitioner and academic analyses of what you can do with these models. They outperform sell-side analysts when picking stocks. They show promise in putting together short-term, long-term, long/short trading strategies based on synthesizing comments from CFOs in conference call transcripts. They are already improving audit quality at the big accounting firms if you use the frequency of audit restatements as a proxy for that. The University of Florida created something called GatorTron to extract insights from terabytes and terabytes of clinical data to help them with medical research.
And in law firms, this is looking interesting. These models have correctly gone through court cases and predicted with the judgements were going to be. They have passed bar exams. They have begun to be used to draft contracts and conduct legal research, et cetera, et cetera. And Microsoft just released MegaTron, which is the largest one of these things to date. So there is evidence that if you narrow down the scope of what you’re asking these models to do, that they can be more productive and do a much better job.
One of the big questions that came out of this, as I mentioned earlier, Google’s stock got pummeled after this rollout. What’s going to happen to the profitability of the search business? Microsoft’s CEO says the gross margins of these, of search is going to drop forever, and Sam Altman is referred to lethargic search monopolies. We know who he’s talking about when he says things like that.
We’ll see. I mean Google knows a lot about machine learning and artificial intelligence. They were the ones that designed some of these initial transformer programs. There’s a lot of machine learning that already is going on within Google Search. And I anticipate a pretty robust response from them soon regarding their capabilities after what happened.
That said, the search economics do look more challenging. Google’s operating margins are about 24%. And that includes YouTube, so obviously without that, they’re higher. But anything that they offer with respect to large language models being integrated into the regular search offering would sit on top of their existing cost structure.
Now ChatGPT’s cost structure is pretty high because they’re not completely vertically integrated, and depending upon the number of words generated per query, the model size, and their computing costs, it can get very expensive for them. And some of the estimates we’ve seen is anywhere from five to ten times more expensive per query compared to the standard Google search query.
But I think it’s important to remember, first, Google has announced that when and if they incorporate large language models into the search engine, it would be a lightweight version instead of its heavy-duty version. So I think the ChatGPT cost estimates probably overstate the impact on Google’s operating margins.
Also, there are things called sparse models. Right now if you use ChatGPT 3, all 175 billion parameters are used to generate a response, and sparse models are built narrowing the field of knowledge that you need to answer a question, and they require a lot less training energy, a lot less computing energy, and actually can work faster.
I know it’s tempting to kind of look at the pace of innovation and see a big threat to Google here on the search side. So far, the ChatGPT/Bing combination has taken like .3% market share on search traffic from Google, whose base market share is above 92%. So I just think it’s important to look at the numbers to keep these things in context.
What’s the future of these things, these large language models? One of the more interesting projects that’s underway is, despite all the hyperbole of what these things can and can’t do, there is about 400 researchers from Google, OpenAI, and 100 other firms, and they’ve put together something called the BIG-bench, which refers to the big benchmark. And they’ve all created about 200 tasks for large language models to solve, and I list a few of them in the Eye in the Markets.
Some of them are interesting. They ask the models to guess what movie they’re referring to when they describe the plot just written in emojis. They have a take-the-GRE exam reading comprehension section where sometimes the right answer is more than one. They read short stories about crime and have to identify who the perpetrator was and the reasoning behind it. They have to see whether they can identify sarcasm or dark humor. You get the point. These are common-sense reasoning capabilities that are often beyond what the current models can do.
And they released the results last summer, and there’s a long way to go. So the aggregate score that Google and OpenAI were getting at the time was about a 15 out of 100, where the average human was a 45, and the best humans were 70 to 80. So these models have a long way to go in understanding things and being able to put things in proper context. The larger the models get presumably, they’ll be able to get better at doing this.
But these large language models, the battles are just beginning. A lot of times their capabilities are overstated. But it will be interesting to watch the narrow, more well-defined tasks that they get asked to do, ‘cause that’s really where the big productivity benefits are going to come from. And my feeling is they’ll probably end up boosting productivity of companies rather than putting legions of people out of work. But we will see. Anyway, take a look at this month’s Eye on the Market, and we get into all of these details and more. Good talking to you, and we’ll see you next time, bye.
FEMALE VOICE: Michael Cembalest’s Eye on the Market offers a unique perspective on the economy, current events, markets, and investment portfolios, and is a production of J.P. Morgan Asset and Wealth Management. Michael Cembalest is the Chairman of Market and Investment Strategy for J.P. Morgan Asset Management and is one of our most renowned and provocative speakers. For more information, please subscribe to the Eye on the Market by contacting your J.P. Morgan representative. If you’d like to hear more, please explore episodes on iTunes or on our website.
This podcast is intended for informational purposes only and is a communication on behalf of J.P. Morgan Institutional Investments Incorporated. Views may not be suitable for all investors and are not intended as personal investment advice or a solicitation or recommendation. Outlooks and past performance are never guarantees of future results. This is not investment research. Please read other important information, which can be found at www.JPMorgan.com/disclaimer/EOTM.
[END RECORDING]