

What was I made for: Large Language Models in the Real World
I asked Chat GPT-4 questions on economics, markets, energy and politics that my analysts and I worked on over the last two years. This piece reviews the results, along with the latest achievements and stumbles of generative AI models in the real world, and comments on the changing relationship between innovation, productivity and employment. The bottom line: a large language model can process reams of text very efficiently, and that’s what it’s made for. But it cannot think or reason; it’s just something I paid for. Upfront, a few comments on oil prices.
Watch the Podcast
[START RECORDING]
FEMALE VOICE 1: This podcast have been prepared exclusively for institutional wholesale professional clients and qualified investors only, as defined by local laws and regulations. Please read other important information which can be found on the link at the end of the podcast episode.
[Music]
MR. MICHAEL CEMBALEST: Hello, everybody. Welcome to the September Eye on the Market video audio podcast. This one's entitled "What Was I Made For: Large Language Models in the Real World." I wanted to focus on this topic again because of how large AI is as a catalyst, what's going on in the equity markets. But first, I just wanted to review economics and market for a minute. Not that much has changed since our August piece called "The Rasputin Effect."
Leading indicators are definitely pointing to weaker growth by the first quarter, but the expected decline is pretty modest as potential recessions go. Tighter credit conditions are certainly going to have an impact, but only 17 or 18 leading indicators that we watch, none of them looks really terrible, they all just look kind of modestly bad, and a little bit weaker.
The reason why things don't look worse after 500 basis points of fed tightening is that the fed policy is being offset by a few things. First of all, very large fiscal deficits, almost as large as they were in 2009. We're having the beginning of a US industrial policy which is essentially incentive-driven spending by the private sector on infrastructure, energy, and semiconductors. That's starting to kick in, but household and corporate balance sheets were pretty strong coming into this year.
Delinquency rates outside subprime auto are still very low. The private sector took actions to lock in low borrowing rates before 2022. Apparently the only entities that didn't get the memo that rates were unsustainably low were a handful of some of the regional banks that you're all familiar with who extended their asset duration at the wrong time.
Housing markets and labor markets are pretty tight, so the normal transmission of higher interest rates and higher fed policy to crater housing and labor markets isn't transmitting quite the same way. So, all of these things are, at least at the current time, kind of keeping a severe recession at bay.
I do want to talk a little bit here about oil prices. The OPEC spare capacity that is pretty high, it's not as high as it gets during recessions as you can see in this chart, but it's pretty high. For a non-recessionary period, OPEC has engineered quite a bit of spare capacity. Now, that can change quickly, but right now spare capacity is pretty tight. You have to combine that with two more things.
First, the publicly traded energy companies are spending a very small share of cash flow. We have a chart in Eye on the Market that shows the percentage of energy company cash flow that they're spending on new projects, specifically oil- and gas-related projects, and that's a very low share, and we juxtapose that against global fossil fuel use. You can see the industry is starting to cut back on future projects for all the reasons you might imagine, even though we really haven't see much decline yet in global oil and gas consumption.
Then on top of that you've got the Strategic Petroleum Reserve at the US at the lowest level it's been in many decades. So, tighter OPEC conditions, less oil and gas investment, and the depleted Strategic Petroleum Reserve, that combines to kind of goose up oil and gas prices, and then we'll have to see what Russia has in store for the world. They've already announced some restrictions on diesel exports.
Higher energy prices tend to feed into inflation within a few months, and so one of the things that you're seeing is the markets were pricing in some fed cuts next year; that's now gone. Now, I did want to focus most of this discussion on generative AI catalyst, because we have a chart in the Eye on the Market this time that shows an ETF for generative AI stocks is up around 60% this year while the market, excluding those stocks, is up around 5%, so this has definitely been the year of generative AI.
I wanted to take a look at how it's being used well and where it's failing, and then perform my own specific test on GPT4 specifically, because I thought it was an interesting exercise. The reason I want to do that is juxtapose these two things. Number one, people are out there comparing large language models to electrification of farms, the interstate highway system, and the internet itself, those are kind of some pretty remarkable milestones.
While at the same time we just lived through a period, whether it was cannabis investing, non-fungible tokens, metaverse, block chain, crypto, hydrogen, where a lot of things were kind of touted to be something that they turned out not to be. So, now we're getting a surge and interest in the large language models, and I think the reality is somewhere in between the nonsense of the metaverse and crypto and the seismic changes introduced by the interstate highway system, and then electrification of farming. So, let's take a closer look.
I started out just doing something lighthearted but still meaningful which is there are these multimodal AI image generation models, and I used three different ones you can see here: Bing, Starry AI, and Dolly, which is GPT's version. I asked it to create an image of two people sitting at the table looking nervously at a robot with them, and that the robot should have a label on it that says "Strategy Team Trainee," like working for me. None of them did it right, and some of them, the mistakes are interesting.
So, starting on the left, first of all, there's three people, not two, and one of the people looks like they're in a horror films, which is pretty scary. Lots of people have extra hands and legs and fingers and things like that. The second one from Starry AI got a little bit closer. You have somebody looking nervously at a robot but there's only one person instead of two, and both the first two ignored the whole thing about the Strategy Team label entirely.
Then you have this Bergmanesque and also fairly terrifying offering from Dolly on the right, splattering some letters on the table, not on the robot, and not really spelling anything. So, I thought this--but still, the interpretative proficiency is good in certain ways, so I thought this mixture of good, bad, and bizarre was a good way of starting this discussion.
Some of you will pick up on the theme of this and the pop culture references I'm using, but when you think about a large language model and something it's made for, here are some examples that are currently working. It's helping management consultants in terms of speed and quality and task completion.
Whether you're impressed with that or not depends on what you think of management consultants. People using Copilot, which is a programming tool, are having a lot of success with it. It's doing a great job on statistics. It's helping people that do professional writing. It's helping customer support agents be more productive. It's improving their employee retention, and a lot of these things tend to help the lower-skilled workers the most. It's even having some successes in medical research.
The one that I thought was interesting, where somebody fed in some of the 70 most notoriously difficult-to-diagnose medical cases just based on the descriptions of the symptoms people were having, and it got two-thirds of the diagnoses correct. Now, you're not going to like all these large language model use cases. People are using them to generate digital mountains of thick content, fake news sites, fake product reviews on Amazon, fake e-books, phishing emails--I spelled phishing wrong because I like fishing so much--I should have spelled it with a P-H.
A lot of this stuff seems designed to profit from Google, essentially fool Google's automated advertising process into paying it for people looking at junk content that they don't really know is AI-generated. In any case, these are the things that it's doing well and where the use cases are expanding.
I saw this chart from Open AI but I wasn't as impressed as I think Open AI wanted me to be. It's a chart that shows how GPT4 is doing versus GPT3.5, taking all sorts of standardized tests. As you can see here, there's math tests and chemistry exams, bar exams, biology exams, history exams, SATs, GREs, things like that.
There's something, I think a lot of you are probably pretty aware of this right now, but there's something called data contamination which is if you train these models on information sets that include the questions and the answers to all these exams, all we're really analyzing is whether or not GPT, or any of the other ones, whether it's Bard or Bing or Anthropic or any of the rest of them, they are good at memorization.
But we know that large language models are good at memorization, so I'm not really sure exactly what's being proven here other than the impact of having 10 times more parameters in GPT4 than GPT3.5 makes it better at memorization.
I think the more important question is you don't hire a lawyer so that he can sit down and answer bar exam questions all day, you hire a lawyer when you need somebody to integrate new information and evaluate things maybe they haven't seen before. When you look at those kinds of tasks, large language models aren't doing quite as well. We have a page in here called "It's not what I'm made for."
When GPT4 has been asked to take law exams it does pretty poorly, and I like the description from the University of Minnesota professors who did this where they said "GPT4 produced smoothly written answers that failed to spot many important issues, much like a bright student who didn't attend class and hadn't thought deeply about the material."
So, now you can get a better feel for what we're dealing with here. It's like repetition rather than real reasoning and thought. GPT4 did terribly on the actuarial exam, a college sophomore economics exam, graduate-level tax and trust and estates exams. It botched Pythagoras' theorem when being asked to be a math teacher. It got stuck in a death loop of nonsense when somebody provided it with mathematically impossible dimensions of triangle that it should have been able to figure out.
The journal had this article where they're writing about how online editors and newspaper editors are being given so many crappy AI-written submissions that they have good spelling and grammar but lack of coherent story. They're just outright rejecting anything that they can get the sense that there was any AI used to generate it at all.
The most comprehensive assessment of large language models that I've seen is something called Big Bench, which is a project that over 400 researchers around the country are working on. There's 204 tasks involved, and the latest that it was updated was July of 2023, of this year, and they still found substantial underperformance of large language models compared to the average human, much less the highly performing human.
Anyway, Manuela Veloso is from Carnegie Mellon and she runs JP Morgan's AI research group, and they're doing a lot of really interesting applications of large language models. She walked me through some of them and I was very impressed. They do seem like they're productivity savers, information checking, information gathering, charting tools, making sure that documents are filled out properly, all of which are mostly designed to reduce errors and omissions, and that's potentially a very powerful and profitable application of a large language model.
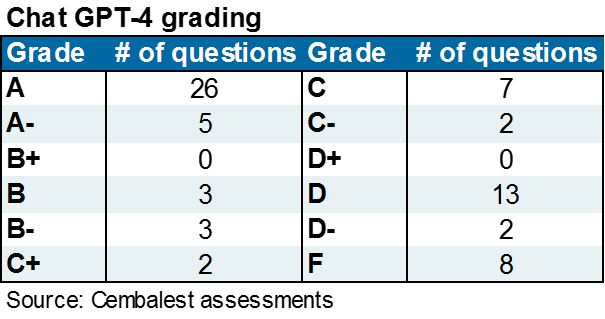
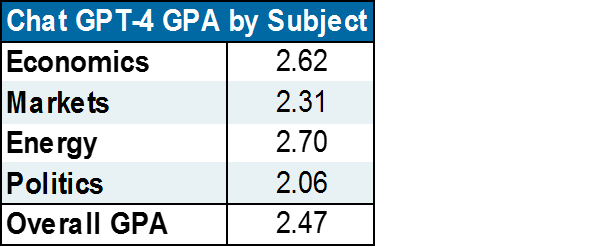
For me, it's a little different. So, here's what I did. I took 71 questions from the Eye on the Market over the last two years that my analyst and I worked on, and I asked ChatGPT4 to take a shot at it, and I graded GPT4 based on its speed, accuracy, and depth, versus the work that we had done ourselves to get the answers. In other words, we're not grading it whether it can do anything, we're grading it compared to the process that we use that didn't yield and hallucinations or errors or things like that.
We enabled the GPT4 features to upload data files when it couldn't find it on its own and needed date files. We enabled the plug-ins that allow it to browse PDFs and Excel files when necessary. So, as a result, a lot of you have read that GPT4 is training data for its parameters ended in 2021. That's not a constraint because we added all the plug-ins to give it all of the data and all of the web access that it needed to answer any of our questions.
So, here are the results. It was a mixed bag, and a very bimodal distribution of grades. It got a lot of As. Out of 71 questions it got 26 As and 25 A-minuses. That sounds great. The problem is, it also got 13 Ds and 6 Fs, so it was very much of a bimodal distribution. The GPA worked out to around 2.5, which is between a C- and B+. You might say, well, what did it get wrong?
Here are some examples of what it did. It would hallucinate numbers and then absolutely refuse to provide a source for where it found them. It was very frustrating. It would outline the correct steps to solve a problem and then execute the steps incorrectly when doing it. It misread data files that we provided to it. It didn't notice when there was data in a spreadsheet and there were subtotals that you should exclude subtotals from when you're summing a column. It messed up some energy conversions, and it also asserted certain facts that are easily contradicted by other readily available information.
So, that was my experience with it, and I guess the bottom line is, just to wrap up, I think GPT4 is going to have a big impact in Manuela's world, for example, since the tasks that she's designed for it conform more to what these things are made for, which is error checking and memorization, most often using trained corporate data and not just trained internet data.
The part that I struggle with the most is how am I supposed to incorporate a tool where even if it can get some answers to complex questions right, I have to check every single answer, because since it sometimes gets things wrong I have to check every answer, and by the time I've done that, where's the productivity gain of using the tool in the first place.
So, anyway, I'm just going to use it for the simpler questions where it performs well. I think that's what it's made for, and at just $20 a month for GPT4, I got what I paid for.
So, that's this month's Eye on the Market. We've got a piece coming up that's a deep dive on New York City and its recovery compared to other major metropolitan areas that I think a lot of our clients will be interested in, and of course, we're going to continue to monitor what's going on with the fed and consumer spending, energy prices, and economic slowdown later this year. Thanks for listening, and I'll see everybody next time.
FEMALE VOICE 1: Michael Cembalest's Eye on the Market offers a unique perspective on the economy, current events, markets, and investment portfolios, and is a production of JP Morgan Asset and Wealth Management. Michael Cembalest is the Chairman of Market and Investment Strategy for JP Morgan Asset Management and is one of our most renowned and provocative speakers.
For more information, please subscribe to the Eye on the Market by contacting your JP Morgan representative. If you'd like to hear more please explore episodes on iTunes or on our website. This podcast is intended for informational purposes only and is a communication on behalf of JP Morgan Institutional Investments, Incorporated.
Views many not be suitable for all investors and are not intended as personal investment advice or a solicitation or recommendation. Outlooks and past performance are never guarantees of future results. This is not investment research. Please read other important information which can be found at www.jpmorgan.com/disclaimer-EOTF.
[END RECORDING]
IMPORTANT INFORMATION
SPAC securities have unique additional risks that you should consider. In particular, in a SPAC structure, the SPAC’s ability to successfully effect a business combination and to be successful thereafter will be particularly dependent, in whole or in part, upon the efforts of the SPAC’s key personnel. Although J.P. Morgan Securities LLC (or its affiliates) will not receive any special compensation (other than customary underwriting compensation) in connection with a SPAC IPO, J.P. Morgan Securities LLC may potentially provide other services and products to the SPAC and/or the SPAC’s key personnel, which may enhance J.P. Morgan’s relationships with such parties, and enable J.P. Morgan to obtain additional business and generate additional revenue from such parties.
This report uses rigorous security protocols for selected data sourced from Chase credit and debit card transactions to ensure all information is kept confidential and secure. All selected data is highly aggregated and all unique identifiable information, including names, account numbers, addresses, dates of birth, and Social Security Numbers, is removed from the data before the report’s author receives it. The data in this report is not representative of Chase’s overall credit and debit cardholder population.
The views, opinions and estimates expressed herein constitute Michael Cembalest’s judgment based on current market conditions and are subject to change without notice. Information herein may differ from those expressed by other areas of J.P. Morgan. This information in no way constitutes J.P. Morgan Research and should not be treated as such.
The views contained herein are not to be taken as advice or a recommendation to buy or sell any investment in any jurisdiction, nor is it a commitment from J.P. Morgan or any of its subsidiaries to participate in any of the transactions mentioned herein. Any forecasts, figures, opinions or investment techniques and strategies set out are for information purposes only, based on certain assumptions and current market conditions and are subject to change without prior notice. All information presented herein is considered to be accurate at the time of production. This material does not contain sufficient information to support an investment decision and it should not be relied upon by you in evaluating the merits of investing in any securities or products. In addition, users should make an independent assessment of the legal, regulatory, tax, credit and accounting implications and determine, together with their own professional advisers, if any investment mentioned herein is believed to be suitable to their personal goals. Investors should ensure that they obtain all available relevant information before making any investment. It should be noted that investment involves risks, the value of investments and the income from them may fluctuate in accordance with market conditions and taxation agreements and investors may not get back the full amount invested. Both past performance and yields are not reliable indicators of current and future results.
Non-affiliated entities mentioned are for informational purposes only and should not be construed as an endorsement or sponsorship of J.P. Morgan Chase & Co. or its affiliates.
For J.P. Morgan Asset Management Clients:
J.P. Morgan Asset Management is the brand for the asset management business of JPMorgan Chase & Co. and its affiliates worldwide.
To the extent permitted by applicable law, we may record telephone calls and monitor electronic communications to comply with our legal and regulatory obligations and internal policies. Personal data will be collected, stored and processed by J.P. Morgan Asset Management in accordance with our privacy policies at https://am.jpmorgan.com/global/privacy.
ACCESSIBILITY
For U.S. only: If you are a person with a disability and need additional support in viewing the material, please call us at 1-800-343-1113 for assistance.
This communication is issued by the following entities:
In the United States, by J.P. Morgan Investment Management Inc. or J.P. Morgan Alternative Asset Management, Inc., both regulated by the Securities and Exchange Commission; in Latin America, for intended recipients’ use only, by local J.P. Morgan entities, as the case may be.; in Canada, for institutional clients’ use only, by JPMorgan Asset Management (Canada) Inc., which is a registered Portfolio Manager and Exempt Market Dealer in all Canadian provinces and territories except the Yukon and is also registered as an Investment Fund Manager in British Columbia, Ontario, Quebec and Newfoundland and Labrador. In the United Kingdom, by JPMorgan Asset Management (UK) Limited, which is authorized and regulated by the Financial Conduct Authority; in other European jurisdictions, by JPMorgan Asset Management (Europe) S.à r.l. In Asia Pacific (“APAC”), by the following issuing entities and in the respective jurisdictions in which they are primarily regulated: JPMorgan Asset Management (Asia Pacific) Limited, or JPMorgan Funds (Asia) Limited, or JPMorgan Asset Management Real Assets (Asia) Limited, each of which is regulated by the Securities and Futures Commission of Hong Kong; JPMorgan Asset Management (Singapore) Limited (Co. Reg. No. 197601586K), which this advertisement or publication has not been reviewed by the Monetary Authority of Singapore; JPMorgan Asset Management (Taiwan) Limited; JPMorgan Asset Management (Japan) Limited, which is a member of the Investment Trusts Association, Japan, the Japan Investment Advisers Association, Type II Financial Instruments Firms Association and the Japan Securities Dealers Association and is regulated by the Financial Services Agency (registration number “Kanto Local Finance Bureau (Financial Instruments Firm) No. 330”); in Australia, to wholesale clients only as defined in section 761A and 761G of the Corporations Act 2001 (Commonwealth), by JPMorgan Asset Management (Australia) Limited (ABN 55143832080) (AFSL 376919). For all other markets in APAC, to intended recipients only.
For J.P. Morgan Private Bank Clients:
ACCESSIBILITY
J.P. Morgan is committed to making our products and services accessible to meet the financial services needs of all our clients. Please direct any accessibility issues to the Private Bank Client Service Center at 1-866-265-1727.
LEGAL ENTITY, BRAND & REGULATORY INFORMATION
In the United States, bank deposit accounts and related services, such as checking, savings and bank lending, are offered by JPMorgan Chase Bank, N.A. Member FDIC.
JPMorgan Chase Bank, N.A. and its affiliates (collectively “JPMCB”) offer investment products, which may include bank-managed investment accounts and custody, as part of its trust and fiduciary services. Other investment products and services, such as brokerage and advisory accounts, are offered through J.P. Morgan Securities LLC (“JPMS”), a member of FINRA and SIPC. Annuities are made available through Chase Insurance Agency, Inc. (CIA), a licensed insurance agency, doing business as Chase Insurance Agency Services, Inc. in Florida. JPMCB, JPMS and CIA are affiliated companies under the common control of JPM. Products not available in all states.
In Germany, this material is issued by J.P. Morgan SE, with its registered office at Taunustor 1 (TaunusTurm), 60310 Frankfurt am Main, Germany, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB). In Luxembourg, this material is issued by J.P. Morgan SE – Luxembourg Branch, with registered office at European Bank and Business Centre, 6 route de Treves, L-2633, Senningerberg, Luxembourg, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – Luxembourg Branch is also supervised by the Commission de Surveillance du Secteur Financier (CSSF); registered under R.C.S Luxembourg B255938. In the United Kingdom, this material is issued by J.P. Morgan SE – London Branch, registered office at 25 Bank Street, Canary Wharf, London E14 5JP, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – London Branch is also supervised by the Financial Conduct Authority and Prudential Regulation Authority. In Spain, this material is distributed by J.P. Morgan SE, Sucursal en España, with registered office at Paseo de la Castellana, 31, 28046 Madrid, Spain, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE, Sucursal en España is also supervised by the Spanish Securities Market Commission (CNMV); registered with Bank of Spain as a branch of J.P. Morgan SE under code 1567. In Italy, this material is distributed by J.P. Morgan SE – Milan Branch, with its registered office at Via Cordusio, n.3, Milan 20123, Italy, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – Milan Branch is also supervised by Bank of Italy and the Commissione Nazionale per le Società e la Borsa (CONSOB); registered with Bank of Italy as a branch of J.P. Morgan SE under code 8076; Milan Chamber of Commerce Registered Number: REA MI 2536325. In the Netherlands, this material is distributed by J.P. Morgan SE – Amsterdam Branch, with registered office at World Trade Centre, Tower B, Strawinskylaan 1135, 1077 XX, Amsterdam, The Netherlands, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – Amsterdam Branch is also supervised by De Nederlandsche Bank (DNB) and the Autoriteit Financiële Markten (AFM) in the Netherlands. Registered with the Kamer van Koophandel as a branch of J.P. Morgan SE under registration number 72610220. In Denmark, this material is distributed by J.P. Morgan SE – Copenhagen Branch, filial af J.P. Morgan SE, Tyskland, with registered office at Kalvebod Brygge 39-41, 1560 København V, Denmark, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – Copenhagen Branch, filial af J.P. Morgan SE, Tyskland is also supervised by Finanstilsynet (Danish FSA) and is registered with Finanstilsynet as a branch of J.P. Morgan SE under code 29010. In Sweden, this material is distributed by J.P. Morgan SE – Stockholm Bankfilial, with registered office at Hamngatan 15, Stockholm, 11147, Sweden, authorized by the Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) and jointly supervised by the BaFin, the German Central Bank (Deutsche Bundesbank) and the European Central Bank (ECB); J.P. Morgan SE – Stockholm Bankfilial is also supervised by Finansinspektionen (Swedish FSA); registered with Finansinspektionen as a branch of J.P. Morgan SE. In France, this material is distributed by JPMCB, Paris branch, which is regulated by the French banking authorities Autorité de Contrôle Prudentiel et de Résolution and Autorité des Marchés Financiers. In Switzerland, this material is distributed by J.P. Morgan (Suisse) SA, with registered address at rue de la Confédération, 8, 1211, Geneva, Switzerland, which is authorised and supervised by the Swiss Financial Market Supervisory Authority (FINMA), as a bank and a securities dealer in Switzerland. Please consult the following link to obtain information regarding J.P. Morgan’s EMEA data protection policy: https://www.jpmorgan.com/privacy.
In Hong Kong, this material is distributed by JPMCB, Hong Kong branch. JPMCB, Hong Kong branch is regulated by the Hong Kong Monetary Authority and the Securities and Futures Commission of Hong Kong. In Hong Kong, we will cease to use your personal data for our marketing purposes without charge if you so request. In Singapore, this material is distributed by JPMCB, Singapore branch. JPMCB, Singapore branch is regulated by the Monetary Authority of Singapore. Dealing and advisory services and discretionary investment management services are provided to you by JPMCB, Hong Kong/Singapore branch (as notified to you). Banking and custody services are provided to you by JPMCB Singapore Branch. The contents of this document have not been reviewed by any regulatory authority in Hong Kong, Singapore or any other jurisdictions. You are advised to exercise caution in relation to this document. If you are in any doubt about any of the contents of this document, you should obtain independent professional advice. For materials which constitute product advertisement under the Securities and Futures Act and the Financial Advisers Act, this advertisement has not been reviewed by the Monetary Authority of Singapore. JPMorgan Chase Bank, N.A. is a national banking association chartered under the laws of the United States, and as a body corporate, its shareholder’s liability is limited.
With respect to countries in Latin America, the distribution of this material may be restricted in certain jurisdictions. We may offer and/or sell to you securities or other financial instruments which may not be registered under, and are not the subject of a public offering under, the securities or other financial regulatory laws of your home country. Such securities or instruments are offered and/or sold to you on a private basis only. Any communication by us to you regarding such securities or instruments, including without limitation the delivery of a prospectus, term sheet or other offering document, is not intended by us as an offer to sell or a solicitation of an offer to buy any securities or instruments in any jurisdiction in which such an offer or a solicitation is unlawful. Furthermore, such securities or instruments may be subject to certain regulatory and/or contractual restrictions on subsequent transfer by you, and you are solely responsible for ascertaining and complying with such restrictions. To the extent this content makes reference to a fund, the Fund may not be publicly offered in any Latin American country, without previous registration of such fund’s securities in compliance with the laws of the corresponding jurisdiction. Public offering of any security, including the shares of the Fund, without previous registration at Brazilian Securities and Exchange Commission— CVM is completely prohibited. Some products or services contained in the materials might not be currently provided by the Brazilian and Mexican platforms.
JPMorgan Chase Bank, N.A. (JPMCBNA) (ABN 43 074 112 011/AFS Licence No: 238367) is regulated by the Australian Securities and Investment Commission and the Australian Prudential Regulation Authority. Material provided by JPMCBNA in Australia is to “wholesale clients” only. For the purposes of this paragraph the term “wholesale client” has the meaning given in section 761G of the Corporations Act 2001 (Cth). Please inform us if you are not a Wholesale Client now or if you cease to be a Wholesale Client at any time in the future.
JPMS is a registered foreign company (overseas) (ARBN 109293610) incorporated in Delaware, U.S.A. Under Australian financial services licensing requirements, carrying on a financial services business in Australia requires a financial service provider, such as J.P. Morgan Securities LLC (JPMS), to hold an Australian Financial Services Licence (AFSL), unless an exemption applies. JPMS is exempt from the requirement to hold an AFSL under the Corporations Act 2001 (Cth) (Act) in respect of financial services it provides to you, and is regulated by the SEC, FINRA and CFTC under U.S. laws, which differ from Australian laws. Material provided by JPMS in Australia is to “wholesale clients” only. The information provided in this material is not intended to be, and must not be, distributed or passed on, directly or indirectly, to any other class of persons in Australia. For the purposes of this paragraph the term “wholesale client” has the meaning given in section 761G of the Act. Please inform us immediately if you are not a Wholesale Client now or if you cease to be a Wholesale Client at any time in the future.
This material has not been prepared specifically for Australian investors. It:
May contain references to dollar amounts which are not Australian dollars;
May contain financial information which is not prepared in accordance with Australian law or practices;
May not address risks associated with investment in foreign currency denominated investments; and
Does not address Australian tax issues.